探索 Microsoft 的 Phi-3 语言模型、其架构、功能和应用的完整指南,以及安装、设置、集成、优化和微调模型的过程。
近日,微软再次为开源社区做出了重大贡献,发布了开放AI模型系列Phi-3模型。
在本文中,我们将深入了解 Phi-3 模型,首先介绍其架构,然后将其与 Llama 和 GPT 等其他模型进行比较。然后,我们将探讨数据集质量和模型对齐方面的进步,这些进步有助于提高 Phi-3 的性能。此外,我们将详细讨论该模型及其变体的独特功能。
在第二部分中,我们将深入研究 Phi-3 模型的实际方面。我们将解释如何使用 Transformers 库访问模型,并在 Hugging Face 的真实数据集上对其进行微调。

什么是 Phi-3?
Phi-3 于 2024 年 4 月 23 日向公众发布。它采用密集的decoder-only Transformer 架构,并使用监督微调 (SFT) 和直接偏好优化 (DPO) 进行了精心微调。
微软“Phi”系列小型语言模型的另一个模型是 Phi-2,这是一个拥有 27 亿个参数的模型。我们的“深入探究 Phi-2 模型”帮助读者了解 Phi-2 模型,并学习如何使用角色扮演数据集访问和微调该模型。
Phi-3 的微调确保它与人类偏好紧密结合并遵守安全准则,使其成为复杂语言理解和生成任务的理想选择。
该模型的性能因包含 3.3 万亿个 token 的高质量训练数据集而显著提升。该数据集来自经过严格筛选的公开文档、高质量教育材料和专门创建的合成数据。如此强大的数据集不仅使模型与人类偏好保持一致,而且还提高了其安全性和可靠性。
Phi-3 型号变体
Phi-3 有几种版本,每种版本都旨在满足不同的计算和应用需求:

- Phi-3-mini:该变体拥有 38 亿个参数,支持 128K 的长上下文长度。值得注意的是,它的性能与 Mixtral 8x7B 和 GPT-3.5 等较大模型相当,并且可以在 iPhone 14 等移动设备上运行。
- Phi-3-small:具有 70 亿个参数和 8K 默认上下文长度,该模型针对需要较少计算能力的任务进行了优化,且不会牺牲性能。
- Phi-3-medium:此型号容量更大,有 40 个头和层,专为更苛刻的计算任务而设计。
这些变体确保用户拥有多种选择,无论他们需要能够在内存有限的便携式设备上运行的模型,还是能够处理最苛刻的 AI 任务的模型。Phi-3 的每个变体都保持着高标准的输出,使其成为推动 AI 技术进步的多功能工具。
Phi-3 与其他语言模型的比较
Phi-3 模型变体(Phi-3-mini、Phi-3-small 和 Phi-3-medium)的性能已在多种基准上与 Mistral、Gemma、Llama-3-In、Mixtral 和 GPT-3.5 等几种著名的 AI 模型进行了评估。
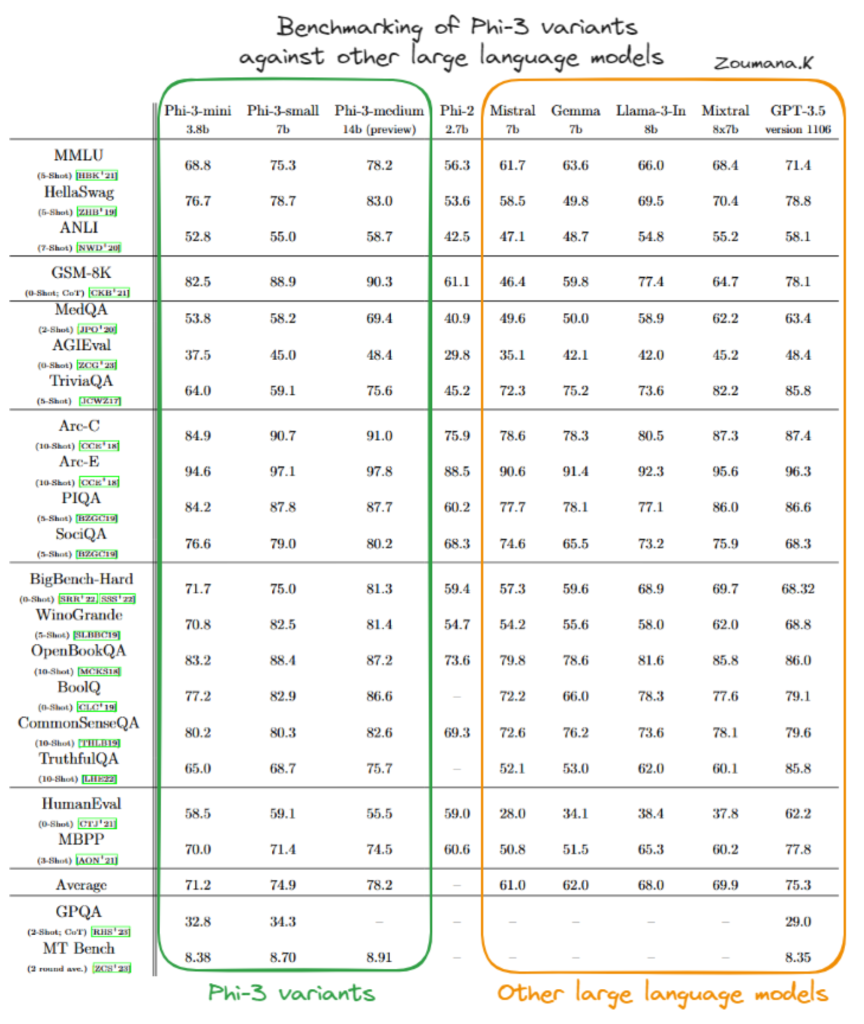
Phi-3-mini
根据上表,我们可以看到 Phi-3-mini 变体通常表现良好,通常与 GPT-3.5 等更大、更复杂的模型的得分相当或超过后者,尤其是在专注于物理推理 (PIQA) 和更广泛的上下文理解 (BigBench-Hard) 的基准测试中。它在这些不同测试中的出色表现证明了它能够有效处理复杂任务。
Phi-3-small
Phi-3-small 虽然并不总是能达到 Phi-3-mini 或 Phi-3-medium 的水平,但在 PIQA 和 BigBench-Hard 等专业领域仍然占有一席之地,在 PIQA 中,它在同类产品中取得了最高分。这表明,即使是 Phi-3 模型的较小变体在其操作参数范围内也是非常有效的。
Phi-3-medium
Phi-3-medium 在几乎所有基准测试中都表现出色,经常取得最高分。其更大的尺寸和容量似乎在需要深度情境理解和复杂推理的任务中提供了显著的优势,展示了其在处理高级人工智能任务方面的稳健性和多功能性。
总体而言,Phi-3 模型在广泛的 AI 基准测试中都具有强大且有竞争力的能力,表明其架构完善且训练方法有效。这使得 Phi-3 变体在 AI 语言模型领域占据主导地位。
Phi-3 的实际应用
Phi-3 在多项基准测试中的强劲表现凸显了其在技术和商业领域彻底改变各种应用的潜力。
以下是 Phi-3 的一些实际应用,重点介绍了数据科学管道中的用例场景和集成技术。
用例场景
Phi-3 的功能可以通过多种创新方式加以利用:
- 聊天机器人: Phi-3 可用于开发复杂的聊天机器人系统,提供更自然、更能感知上下文的交互。它能够理解和生成类似人类的文本,这使其成为客户服务、虚拟协助和交互式媒体的理想选择。
- 数据分析:该模型可以分析大量文本数据以提取见解、趋势和模式,这些在市场分析、研究和决策过程中非常有价值。
- 内容生成: Phi-3 擅长生成连贯、语境相关且风格多样的书面内容。这使得它适合内容营销、创意写作和媒体制作等应用。
与数据科学管道集成
将 Phi-3 集成到数据科学工作流程中涉及几个关键步骤:
- 数据预处理:在将数据输入 Phi-3 之前,清理和准备数据非常重要。这可能涉及消除噪音、标准化格式以及将文本分割成与模型训练数据一致的可管理块。
- 模型集成: Phi-3 可以使用 API 或将其部署为微服务集成到现有的数据科学管道中。这种灵活性使模型能够动态处理数据并根据可用的计算资源进行扩展。
- 输出的后处理: Phi-3 生成输出后,可能需要进一步处理以优化这些结果。这可能包括过滤输出、应用业务规则,甚至使用辅助模型来提高最终输出质量。
Phi-3 最佳实践
在部署和推理 Phi-3 模型时,某些最佳实践可以帮助最大限度地提高性能、有效管理资源并确保模型能够根据应用程序的需求进行适当扩展。以下是一些基本提示:
硬件利用率
- 通过为作业选择合适的处理单元来优化硬件资源。例如,GPU 通常更适合微调和高速推理,而对于要求不高的任务,CPU 可能更具成本效益。
- 利用 TPU 等专用硬件来进一步提高性能,尤其是对于像 Phi-3 这样具有大量计算要求的模型。
模型选择
- 使用 Phi-3-mini在各种任务中实现性能和资源效率的良好平衡。
- 在资源受限的情况下或性能不是最高优先级时使用 Phi-3-small 。
- 如果需要顶级性能和高精度,并且有足够的计算资源,请使用 Phi-3-medium。
如何设置Phi-3
在深入研究 Phi-3 模型的微调方面之前,本节重点介绍使用 Transformers、accelerate、auto-gptp 和 optimal 库在推理模式下运行 Phi-3 模型的主要步骤,这可以帮助用户熟悉该工具。
pip install -qqq accelerate transformers auto-gptq optimum
然后按如下方式导入必要的模块:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
为了可重复性,sed 被设置为一个常数值,在我们的例子中对应于 2024,但它可以是任何数字,只要在所有不同的运行中使用相同的数字即可。
set_seed(2024)
prompt = "Africa is an emerging economy because"
model_checkpoint = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_checkpoint,
trust_remote_code=True,
torch_dtype="auto",
device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=120)
response= tokenizer.decode(outputs[0], skip_special_tokens=True)
我们先来理解一下上面的代码:
- 代码初始化使用微软语言模型(“Phi-3-mini-4k-instruct”)来完成给定的文本提示。
- 它使用标记器将提示转换为机器可读的格式,并指导计算通过 CUDA 利用 GPU 加速。
- 最后,它为提示生成一个文本延续并将其解码为可读文本,完成以“Africa is an emerging economy because”开头的提示。
成功运行上述代码后,使用以下打印语句显示结果:
print(response)

该模型提供了非洲被视为新兴市场的四个主要原因(A、B、C 和 D)。Bob 随后开始详细阐述每个原因,从 A 开始。然而,答案以“非洲大陆一直是”结尾。这是因为我们将 token 的最大数量限制为 120。值越大,模型越自由地生成更多内容。
在这种情况下,模型的响应是叙述,并且“鲍勃”是用于解释的假设说话者。
如何微调Phi-3
在本节中,我们将使用来自 Hugging Face 的 OpusSamantha 数据集对 Microsoft Phi-3 mini 4k 指导模型进行微调。
提供的代码受到macadeliccc关于 Hugging Face 的文章的启发。
微调硬件要求
为了成功运行微调过程,访问具有大量计算资源的系统非常重要。
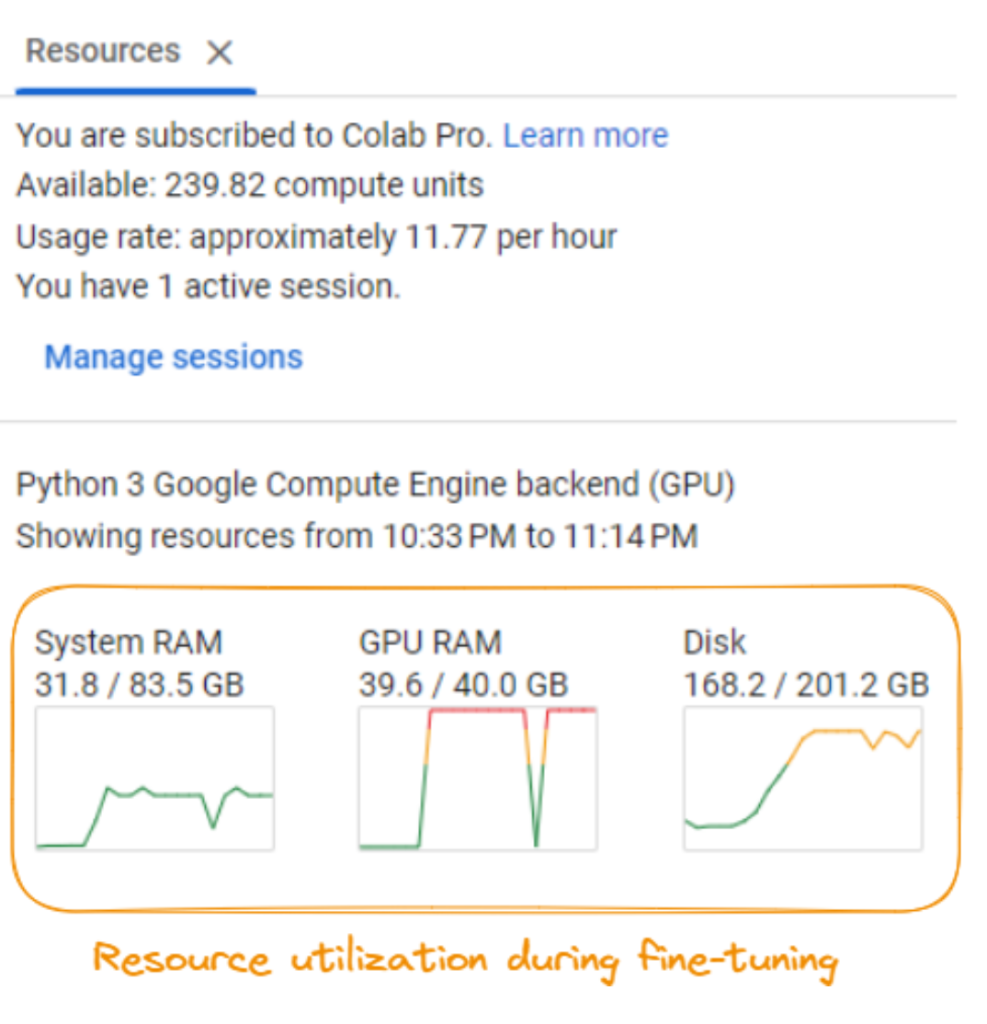
根据截图,要求包括:
- 系统 RAM:至少需要大约 31.8 GB 的系统 RAM。
- GPU RAM:需要具有至少 40.0 GB 专用 RAM 的 GPU。
- 磁盘空间:确保您至少有 201.2 GB 的可用磁盘空间。
- 计算能力:微调过程每小时大约消耗 11.77 个计算单元,并且该消耗会根据微调持续时间而快速累积。
这些要求可能因具体模型、数据集和微调配置而异。建议您使用强大的 GPU 服务器或云计算资源,以有效处理微调过程的计算需求。
步骤 1:设置
首先,我们需要安装微调所需的 Python 库:
%%bash
pip -q install huggingface_hub transformers peft bitsandbytes
pip -q install trl xformers
pip -q install datasets
pip install torch>=1.10
这将安装 Hugging Face Transformers 库、用于高效微调的 Peft 库、用于优化数据加载的 Bitsandbytes 库、用于序列到序列训练的 TRL 库、用于优化注意力操作的 Xformers 库以及用于数据处理的 Datasets 库。
第 2 步:导入所需库并设置配置
接下来,我们导入所需的库并设置微调过程的配置:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from huggingface_hub import ModelCard, ModelCardData, HfApi
from datasets import load_dataset
from jinja2 import Template
from trl import SFTTrainer
import yaml
import torch
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
NEW_MODEL_NAME = "opus-samantha-phi-3-mini-4k"
DATASET_NAME = "macadeliccc/opus_samantha"
SPLIT = "train"
MAX_SEQ_LENGTH = 2048
num_train_epochs = 1
license = "apache-2.0"
learning_rate = 1.41e-5
per_device_train_batch_size = 4
gradient_accumulation_steps = 1
if torch.cuda.is_bf16_supported():
compute_dtype = torch.bfloat16
else:
compute_dtype = torch.float16
我们设置模型 ID、新模型名称、数据集名称、要使用的分割(训练)、最大序列长度、训练周期数、许可证、用户名、学习率、批处理大小和梯度累积步骤。我们还检查 GPU 是否支持 bfloat16 精度并相应地设置计算 dtype。
步骤 3:加载模型、标记器和数据集
接下来,我们加载预先训练的 Phi-3 模型、相应的标记器和 OpusSamantha 数据集:
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True)
dataset = load_dataset(DATASET_NAME, split="train")
步骤 4:预处理数据集
我们通过将对话格式化为提示和响应来预处理数据集:
EOS_TOKEN=tokenizer.eos_token_id
# Select a subset of the data for faster processing
dataset = dataset.select(range(100))
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = []
mapper = {"system": "system\n", "human": "\nuser\n", "gpt": "\nassistant\n"}
end_mapper = {"system": "", "human": "", "gpt": ""}
for convo in convos:
text = "".join(f"{mapper[(turn := x['from'])]} {x['value']}\n{end_mapper[turn]}" for x in convo)
texts.append(f"{text}{EOS_TOKEN}")
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
print(dataset['text'][8])
我们定义一个formatting_prompts_func函数,它接收对话并将其格式化为提示响应格式,并添加适当的前缀和后缀。然后我们使用 将此函数应用于数据集dataset.map。
步骤 5:设置训练参数
接下来,我们为微调过程设置训练参数:
args = TrainingArguments(
evaluation_strategy="steps",
per_device_train_batch_size=7,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=1e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
max_steps=-1,
num_train_epochs=3,
save_strategy="epoch",
logging_steps=10,
output_dir=NEW_MODEL_NAME,
optim="paged_adamw_32bit",
lr_scheduler_type="linear")
在这里,我们设置各种参数,例如评估策略、批量大小、梯度累积步骤、梯度检查点、学习率、精度(fp16 或 bf16)、最大步数、时期数、保存策略、记录频率、输出目录、优化器和学习率调度程序类型。
步骤 6:微调模型
最后,我们创建一个实例SFTTrainer并微调模型:
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=128,
formatting_func=formatting_prompts_func
)
trainer.train()
我们创建一个SFTTrainer对象,传入预训练模型、训练参数、预处理数据集、文本字段名称、最大序列长度和格式化函数。然后,我们调用该train()方法来启动微调过程。
步骤7:微调结果
微调过程的输出在最后打印:
TrainOutput(global_step=9, training_loss=0.7428549660576714, metrics={'train_runtime': 570.4105, 'train_samples_per_second': 0.526, 'train_steps_per_second': 0.016, 'total_flos': 691863632216064.0, 'train_loss': 0.7428549660576714, 'epoch': 2.4})
微调过程经过 2.4 个 epoch 后,训练损失为 0.7428549660576714,训练运行时间约为 570.4105 秒。该模型实现了每秒 0.526 个样本和每秒 0.016 步的训练速度。
至此,Phi-3 模型的微调过程结束。微调后的模型现在可用于进一步的任务和评估。
要了解有关微调大型语言模型的更多信息,我们的《微调 LLM 入门指南》教程将指导您完成使用 Hugging Face 对 GPT-2 等模型进行微调的过程。
结论
本指南对 Phi-3 语言模型进行了深入探讨,帮助读者深入了解其独特的功能、实际应用和有效的利用策略。
在深入探讨 Phi-3 的核心特性和能力之前,我们介绍了该模型的架构及其对各种人工智能和自然语言处理应用的潜在影响。
然后,我们介绍了 Phi-3-mini 的安装和设置过程,逐步演示了如何加载和调用模型来执行简单的文本生成任务,让学习者熟悉该过程。
实践的第二部分涵盖了在自定义数据集上对 Phi-3-mini 模型进行微调以完成专门任务的所有必要步骤,以及拥有充足的训练资源的重要性。
目前有许多大型语言模型,使用正确模型的关键是了解应用程序的要求和模型的功能,以便为当前的任务做出最佳选择。