
你有没有遇到过这样的烦恼:用PyTorch辛辛苦苦训练好的模型,却发现生产环境只支持TensorFlow?或者模型在研究环境表现完美,但部署到移动设备后慢得像蜗牛爬行?如果有,那么今天我要介绍的”翻译官”可能会让你眼前一亮!
在AI的多语言世界里,PyTorch说着一种语言,TensorFlow说着另一种,而各种部署环境又有自己的方言。这种”语言障碍”常常让开发者头疼不已。这就是为什么我们需要一个优秀的”翻译官”,而ONNX正是担此重任的不二人选。
ONNX:AI界的”万能转换器”
想象一下,如果世界上所有的电源插头都统一规格,那该多方便啊!在AI领域,ONNX(Open Neural Network Exchange,开放神经网络交换)就扮演着这样的”万能转换器”角色。它让你可以在喜欢的框架中训练模型,然后轻松地将其部署到任何支持的平台上。
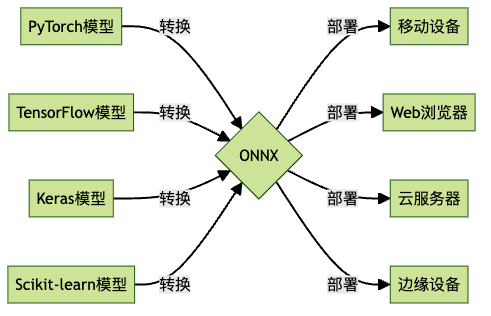
这就像是AI世界的”世界语”——不管你说”TensorFlow语”还是”PyTorch语”,通过ONNX这个翻译官,大家都能互相理解和交流。ONNX不仅能理解多种框架的”方言”,还能将它们翻译成任何部署环境都能理解的通用语言。是不是很酷?
ONNX Runtime:模型的高性能”发动机”
如果说ONNX是一份设计图纸,那么ONNX Runtime就是根据这份图纸组装并驱动机器的”发动机”。它能让你的模型在各种硬件上高效运行,无需关心底层细节。
想象一下,你有一辆能在各种路况下自动调整性能的车——ONNX Runtime就是这样一个神奇的引擎,它能根据你的硬件环境自动调整,让模型跑得更快更稳!
为什么你应该关注ONNX?
1. 告别”框架锁定”的噩梦
还记得VHS和Betamax的格式之争吗?(好吧,我猜大多数读者可能不记得了😅)在AI领域,各种框架的”混战”同样令人头疼,就像不同国家使用不同的语言一样,造成了沟通障碍。
使用ONNX这个”翻译官”,你可以:
- 今天用PyTorch训练,明天用TensorFlow部署
- 在研究环境用一套工具,在生产环境用另一套
- 轻松应对项目需求变更带来的框架切换
就像你可以将Word文档转为PDF一样简单!ONNX成功打破了AI框架间的语言壁垒。
2. 性能提升不是一点点
“我的模型在生产环境太慢了!”——这是很多数据科学家的痛点。使用ONNX Runtime后,很多用户报告性能提升了2-4倍,有些场景甚至更多!
为什么会有如此大的提升?
- ONNX Runtime内置了众多优化技术
- 自动利用硬件加速(CPU、GPU、NPU等)
- 针对推理场景的专门优化
想象一下:同样的模型,运行速度提升3倍,这意味着你可以处理3倍的请求,或者节省2/3的计算资源!
3. 跨平台部署从未如此简单
你是否梦想过:
- 同一个模型可以在服务器、手机、IoT设备上运行?
- 不需要为每个平台重新训练或调整模型?
- 一次开发,到处部署?
ONNX让这些成为可能!从高性能服务器到资源受限的边缘设备,ONNX模型都能高效运行。
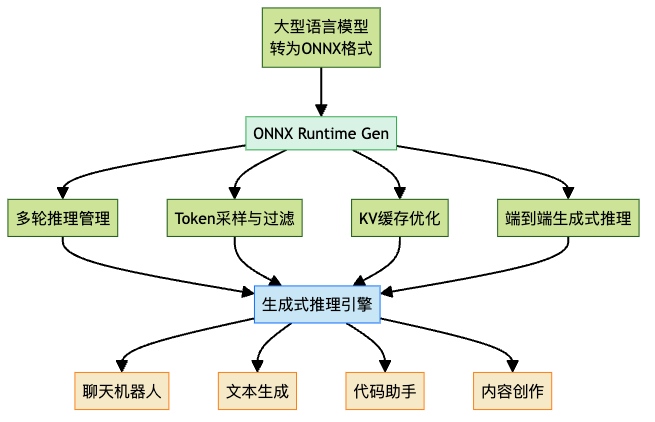
ONNX Runtime Gen:生成式AI的新宠
随着生成式AI(如大型语言模型)的兴起,ONNX家族也推出了专门的工具:ONNX Runtime Gen。它专为处理生成式模型的特殊需求而设计,包括:
执行提供程序:ONNX Runtime的”超能力”来源
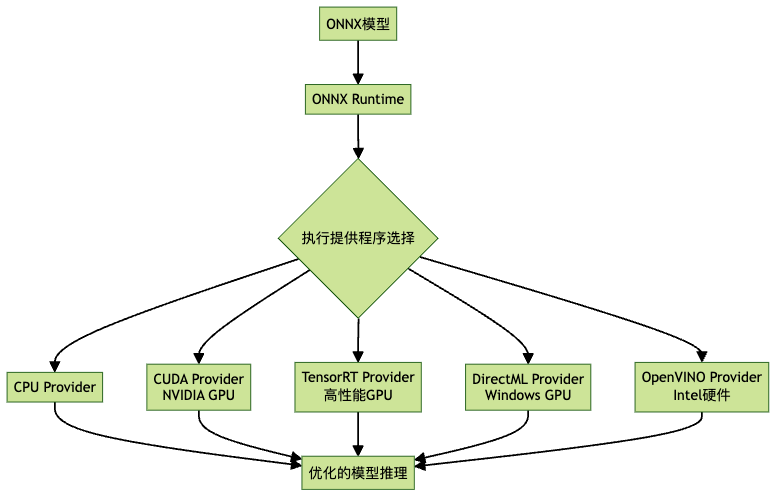
ONNX Runtime最强大的特性之一是其可插拔的”执行提供程序”(Execution Provider)系统。它就像是一个适配器,能让你的模型在各种硬件上发挥最佳性能。
常见的执行提供程序包括:
| 执行提供程序 | 适用硬件 | 特点 |
|---|---|---|
| CPU EP | 通用CPU | 兼容性最好,适用所有设备 |
| CUDA EP | NVIDIA GPU | 利用CUDA加速,适合深度学习 |
| TensorRT EP | NVIDIA GPU | 极致优化的GPU性能 |
| DirectML EP | Windows GPU | 适用于Windows平台的GPU加速 |
| OpenVINO EP | Intel硬件 | 优化Intel CPU/GPU/VPU性能 |
| CoreML EP | Apple设备 | 针对iOS/macOS设备优化 |
使用方法也非常简单:
import onnxruntime as ort
# 指定使用CUDA执行提供程序
session = ort.InferenceSession(
"my_model.onnx",
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)这就像告诉你的AI:”嘿,优先使用GPU,如果不行再用CPU”。
真实案例:ONNX在行动
让我们看看一些真实的ONNX应用案例:
案例1:移动应用中的人脸识别
某移动应用需要在手机上实现实时人脸识别,但直接部署PyTorch模型会导致应用过大且运行缓慢。
解决方案:
- 将PyTorch模型转换为ONNX
- 使用ONNX Runtime Mobile部署
- 利用手机GPU加速(通过适当的执行提供程序)
结果:应用大小减少60%,识别速度提升3倍,电池消耗降低40%。
案例2:多框架模型的微服务架构
一个金融科技公司有多个模型,分别用不同框架开发(PyTorch、TensorFlow、Scikit-learn)。维护多个框架版本的依赖成为运维噩梦,各个模型就像说着不同”方言”的团队,沟通困难。
解决方案:
- 将所有模型统一转换为ONNX格式,让它们说同一种”语言”
- 使用ONNX Runtime部署微服务
- 根据不同服务器硬件选择最佳执行提供程序
结果:服务器依赖大幅简化,部署流程统一,性能提升平均达35%,资源利用率提高50%。这个案例完美展示了ONNX作为”翻译官”的价值。
常见问题解答
Q1: ONNX支持哪些框架的模型?
几乎所有主流机器学习框架都支持ONNX导出,包括但不限于:
- PyTorch
- TensorFlow/Keras
- Scikit-learn
- MXNet
- PaddlePaddle
- Core ML
- CNTK
如果你的框架没有直接支持,通常也有第三方转换工具可用。
Q2: 转换后的模型会损失精度吗?
理论上,ONNX转换是”无损”的,即转换后的模型应该产生与原始模型相同的结果。但在实践中,可能会因为以下原因出现细微差异:
- 数值精度差异(如float32与float16)
- 某些高级操作的实现差异
- 不同框架中默认参数的差异
解决方法是在转换后进行验证,确保结果在可接受范围内。大多数情况下,差异非常小,不会影响模型的实际应用。
结语:ONNX – 连接AI研究与应用的桥梁
ONNX作为AI界的”翻译官”,正在改变AI模型从研究到生产的部署方式。它不仅能够精准翻译各种框架的”语言”,实现框架间的互操作性,还大大简化了模型部署流程,并带来了显著的性能提升。
正如一个优秀的翻译家能够让不同文化背景的人无障碍交流,ONNX让各种AI框架和部署环境和谐共处,从而使开发者能够自由选择最适合的工具,而不必担心后续的兼容问题。
无论你是数据科学家、AI研究员还是应用开发者,ONNX都能帮你解决模型部署的痛点,让你的AI模型在任何平台上”飞”起来!
最后送你一句话:模型训练很重要,但高效部署才是让AI真正发挥价值的关键。ONNX让你的模型不仅能在实验室”跑”,更能在现实世界中”飞”!
欢迎在评论区分享你使用ONNX的经验和问题,我们一起探索AI部署的无限可能!