
嘿,朋友!是不是被琳琅满目的机器学习算法搞得头晕眼花?别担心,只需20分钟,我就能帮你理清这些算法的来龙去脉,让你明白在什么情况下该用哪个算法!
机器学习:是什么?为什么?怎么做?
机器学习,按照维基百科的说法,是人工智能的一个分支,专注于开发能够从数据中学习并泛化到未见数据的统计算法,从而在没有明确指令的情况下完成任务。简单说,就是让计算机自己学会解决问题,而不是我们一步步告诉它怎么做。
近年来AI的爆炸式发展,很大程度上是由神经网络驱动的。不要被这个术语吓到,读完这篇文章,你会对它有一个直观的认识。
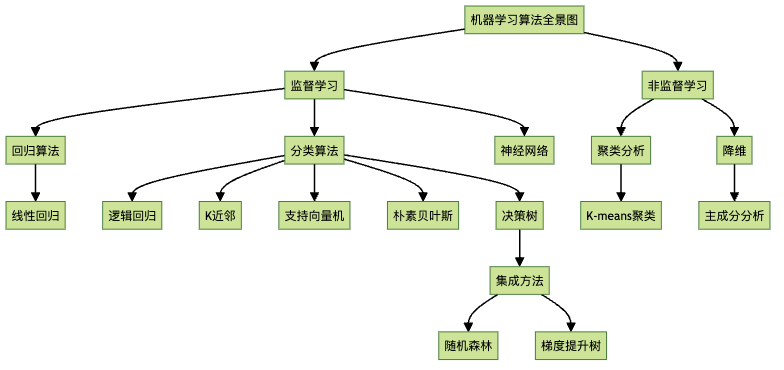
机器学习的两大门派
机器学习主要分为两大类:监督学习和非监督学习。
监督学习:有答案的学习
想象你带着一个小孩学认动物。你指着一张猫的图片说”这是猫”,指着一张狗的图片说”这是狗”。多学习几次后,给他看一张新的动物图片,他就能识别出是猫还是狗。这就是监督学习的本质!
在监督学习中,我们有一些带有”正确答案”(标签)的数据,用来训练算法,然后算法就能预测新数据的答案。例如:
- 根据房屋的面积、位置、建造年份等特征预测房价
- 根据动物的高度、重量、耳朵大小、眼睛颜色等特征将其分类为猫或狗
非监督学习:自己摸索的学习
现在想象你给一个从未见过猫狗的小孩一堆动物图片,让他按照相似性分组,但不告诉他分组标准。他可能会根据大小、颜色或其他特征自己创建分组。这就是非监督学习!
在非监督学习中,我们没有”正确答案”,算法需要自己发现数据中的模式或结构。例如:
- 将所有电子邮件自动分为三类,你之后可以查看并命名这些类别
监督学习的两大分支
监督学习进一步分为两类:回归和分类。
回归:预测数值
回归问题是要预测一个连续的数值。比如预测房价、股票价格、明天的温度等。
例如,我们可能发现房屋面积与房价成正比(线性关系),但房屋年龄与房价可能没有关系。
分类:预测类别
分类问题是要将数据点分配到离散的类别中。比如识别邮件是垃圾邮件还是正常邮件,识别图片中是猫还是狗等。
Gmail把邮件分为”垃圾邮件”、”主要”、”社交”、”促销”和”更新”,这就是一个多类别分类问题。
算法大观园:各显神通
好了,现在我们来认识一下各种常见的机器学习算法:
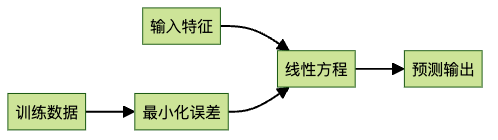
1. 线性回归:万物之母
线性回归是机器学习的”hello world”,也是所有算法的鼻祖。它试图找出输入变量和输出变量之间的线性关系。
想象一下,我们要预测一个人的身高和鞋码之间的关系。线性回归可能会告诉我们:鞋码每增加1个单位,身高平均增加2英寸。
2. 逻辑回归:二分天下
别被名字骗了,逻辑回归实际上是一个分类算法!它是线性回归的变种,用于预测分类输出变量。
比如,我们想根据身高和体重预测一个人的性别。逻辑回归会拟合一个S形的”sigmoid函数”,这个函数能告诉我们,一个身高180厘米的成年人是男性的概率是80%(这个数字是编的哦)。
3. K近邻算法:近朱者赤
K近邻(KNN)是一个超级直观的算法,可用于回归和分类。它的思想很简单:对于任何新数据点,我们预测它的目标值为其K个最近邻居的平均值或多数值。
在分类示例中,我们可能会说一个人的性别与在体重和身高方面最接近的5个人中的大多数相同。在回归示例中,我们可能会说一个人的体重是在身高和胸围方面最接近的3个人的平均体重。
选择合适的K值是一门艺术:K太小会导致”过拟合”(对训练数据预测得很好,但对新数据泛化能力差),K太大会导致”欠拟合”(整体预测能力差)。
4. 支持向量机:划清界限
支持向量机(SVM)是一种强大的分类算法,它试图在数据点之间画一条决策边界,尽可能好地分离不同类别的数据点。
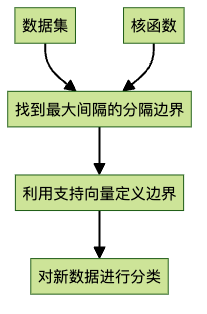
想象我们尝试根据动物的体重和鼻子长度来分类猫和大象。在这个简单的例子中,决策边界是一条直线。SVM算法尝试找到使类别之间间隔最大的线,这使得决策边界对噪声和异常值不太敏感。
SVM的一个强大特性是使用”核函数”,这允许识别高度复杂的非线性决策边界。这就像隐式地创建更复杂的新特征,比如”体重除以身高的平方”(也称为BMI)。这被称为隐式特征工程。
5. 朴素贝叶斯:单纯也是优点
朴素贝叶斯分类器基于贝叶斯定理,最常用于文本分类任务。
想象我们在构建垃圾邮件过滤器。我们可以统计各种单词在垃圾邮件和正常邮件中出现的概率,然后根据新邮件中包含的单词快速分类。我们简单地将邮件中所有单词的概率相乘。
这个算法之所以”朴素”,是因为它假设所有特征(比如单词)之间是相互独立的,这在现实中几乎不可能。但即便如此,它仍然是一个计算效率高且效果不错的算法。
6. 决策树:一问一答
决策树是一系列”是/否”问题,允许我们在多个维度上划分数据集。
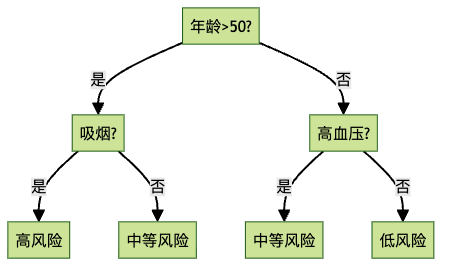
决策树算法的目标是创建尽可能”纯净”的叶节点,即尽量让分类错误的数据点最少。虽然单个决策树可能看起来很简单,但通过组合多个决策树,我们可以创建非常强大的模型。
7. 随机森林:三个臭皮匠,胜过诸葛亮
随机森林是一种”集成算法”,它将多个简单模型组合成一个更强大的复杂模型。在随机森林中,我们训练多个决策树,每个树使用数据的不同子集和特征子集,然后让它们通过多数投票来决定最终分类。
随机森林的”随机性”来自于为不同的树随机排除一些特征,这防止了过拟合,使其更加健壮,因为它减少了树之间的相关性。
8. 梯度提升树:精益求精
另一种集成方法是”提升”,我们按顺序训练模型,每个模型都专注于修复前一个模型犯的错误。我们将一系列弱模型按顺序组合,从而成为一个强模型。
提升树通常比随机森林获得更高的准确性,但也更容易过拟合。它的顺序性质也使其训练速度比随机森林慢。
9. 神经网络:模仿大脑的魔法
让我们再看看逻辑回归。假设我们有一些特征,试图预测一个目标类别。特征可能是图像的像素强度,目标可能是将图像分类为0到9中的某个数字。
这对于逻辑回归来说很困难,因为即使是同一个人写的数字”1″在不同时间看起来也会略有不同。但所有”1″都有共同点,如它们都有一条主要的垂直线,通常没有交叉线,也没有像数字”8″或”9″那样的圆形。
神经网络通过在输入和输出变量之间添加额外的”隐藏层”来自动设计这些特征。每个隐藏层代表一些未知的隐藏特征。
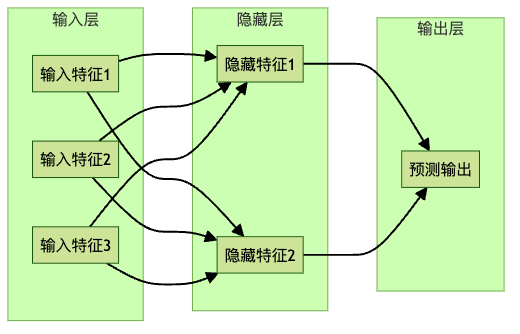
在我们的例子中,每当几个像素挨在一起被照亮时,它们可能代表一条水平线,这可以成为预测数字的新特征,即使我们从未明确定义一个叫做”水平线”的特征。
当我们添加更多的层时,这就成了”深度学习”,可以产生非常复杂的隐藏特征,这些特征可能代表图片中的各种复杂信息,如图片中是否有人脸。然而,我们通常不知道这些隐藏特征的含义,我们只知道它们能产生良好的预测效果。
非监督学习的世界
1. 聚类分析:物以类聚
聚类是一个常见的非监督问题。容易将聚类与分类混淆,但它们在概念上非常不同:
- 分类:我们知道要预测的类别,并有带有真实标签的训练数据
- 聚类:我们没有标签,只是通过查看数据的整体结构来寻找潜在的聚类

最著名的聚类算法是K-means聚类。同样,K是一个超参数,表示你要寻找的聚类数量。找到正确的聚类数量需要一些尝试和领域知识。
K-means的步骤非常简单:
- 随机选择K个聚类中心
- 将所有数据点分配到最近的聚类中心
- 根据现在分配给它们的数据点重新计算聚类中心
- 重复步骤2和3,直到聚类中心稳定下来
2. 降维:化繁为简
降维的思想是减少数据集的特征或维度数量,同时保留尽可能多的信息。这组算法通过寻找现有特征之间的相关性并删除可能冗余的维度来实现这一点。
例如,如果我们试图根据鱼的多个特征(如长度、高度、颜色、牙齿数量等)预测鱼的类型,我们可能会发现高度和长度强烈相关。包含这两者可能对算法没有太大帮助,实际上可能会引入噪声。我们可以简单地包含一个形状特征,它是两者的组合。
主成分分析(PCA)是一种常见的降维算法,它通过找到数据中保留最大方差的方向来实现这一点。在我们的例子中,方差最大的方向是对角线,这被称为第一主成分,可以成为我们新的形状特征。
如何选择正确的算法?
如果你仍然不知道该使用哪种算法,别担心!scikit-learn有一个很棒的算法选择流程图,可以帮助你根据问题类型选择正确的算法。
那么,你的机器学习之旅从哪里开始?如果你想深入了解机器学习,建议先掌握基础的线性回归和逻辑回归,然后逐步探索更复杂的算法。实践是最好的学习方法,找一个感兴趣的项目,应用这些算法,你会发现机器学习其实没那么神秘!
记住,选择正确的算法只是机器学习过程的一部分。数据预处理、特征工程、模型评估和调优同样重要。不过,有了这份20分钟的速成指南,你已经比大多数人更了解机器学习算法了!
祝你的AI之旅愉快!如果你想学习如何实际应用这些算法,不妨看看scikit-learn这个Python库,它提供了我们讨论的所有算法的简单实现。