
想象一下,如果你要买一套房子,你会关注哪些因素?可能是价格、面积、卧室数量、交通便利度等。但你会关心房子的墙纸颜色或者门把手的材质吗?大概率不会,因为这些因素对你的决策影响微乎其微。
机器学习也是如此。当我们训练AI模型时,并非所有特征都能起到积极作用,有些甚至会”添乱”。这就是为什么我们需要”特征选择”——AI模型的”瘦身术”。
什么是特征选择?
特征选择是从原始数据中筛选出最相关、最重要特征的过程,它能让模型更加高效、准确。想象你在为模型”减肥”,去除那些”赘肉”(无关特征),只保留”肌肉”(有用特征)。
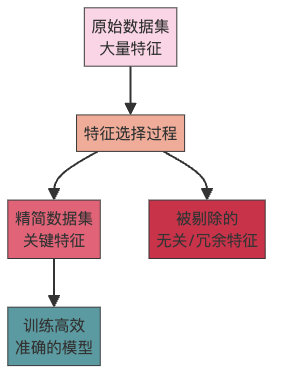
为什么要做特征选择?
“数据越多越好”这句话并不总是对的。特征选择就像是厨师选材,不是所有食材都要放进锅里,而是精选那些能提升菜肴风味的。
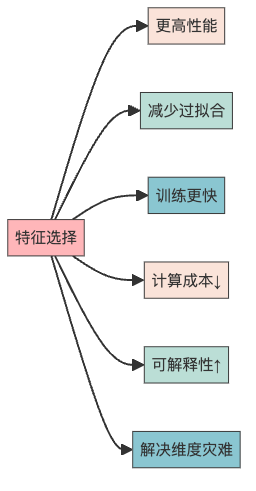
特征选择带来的好处包括:
- 模型性能提升:就像去掉菜里的杂质,模型变得更加精准
- 减少过拟合:模型不再死记硬背训练数据,而是学会了”举一反三”
- 训练时间缩短:少了无用特征的干扰,训练速度嗖嗖的
- 计算成本降低:模型变”轻”了,运行起来自然省电省钱
- 模型更易解释:简单模型就像简单的数学公式,人类更容易理解
- 维度灾难的克星:高维空间里数据稀疏,特征选择能缓解这个问题
特征是什么?
在深入特征选择之前,我们先理解什么是”特征”。特征就是数据的属性或特性,就像人的身高、体重、年龄一样,是描述数据点的可测量特性。
特征可以分为两大类:
- 数值型特征:可以量化的特征,如长度、价格、时长等
- 类别型特征:非数值的特征,如颜色、职位、地点等
拿房屋数据集来说,”卧室数量”、”建筑年份”、”面积”都是特征。特征选择的目标就是找出哪些特征对预测房价最有影响。
监督学习的特征选择方法
在监督学习中,我们有目标变量(如房价),特征选择就是找出哪些输入特征(如面积、位置)对预测目标变量最有帮助。

过滤方法:数据筛子
过滤方法就像是一个筛子,直接基于特征自身的统计特性来评估特征的重要性,而不考虑模型。这些方法速度快、效率高,但可能会错过一些特征间的相互作用。
常见的过滤方法包括:
- 信息增益:测量特征存在与否对减少目标变量不确定性的影响
- 互信息:评估两个变量之间的相互依赖程度
- 卡方检验:检验类别特征与目标变量之间的关联
- 皮尔逊相关系数:量化两个连续变量之间的线性关系
- 方差阈值:删除方差低于阈值的特征,因为低方差特征可能信息量不足
- 缺失值比例:计算特征的缺失值比例,缺失过多的特征可能不够有用
过滤方法就像是餐厅的初步筛选,快速剔除那些明显不合格的”食材”。
包装方法:模型试衣间
包装方法更像是”试衣间”,让模型尝试不同的特征组合,看哪种组合效果最好。这些方法直接考虑模型性能,但计算成本较高。
常见的包装方法有:
- 前向选择:从空集开始,逐个添加提升性能最大的特征
- 后向选择:从全集开始,逐个移除影响最小的特征
- 递归特征消除:反复训练模型并移除最不重要的特征
- 穷举特征选择:测试所有可能的特征组合(计算量巨大!)
包装方法就像是亲自试穿每一件衣服,费时但效果好。
嵌入方法:模型内置选择器
嵌入方法是在模型训练过程中自动进行特征选择,它们像是模型的”内置选择器”。
主要的嵌入方法包括:
- LASSO回归:通过惩罚系数将不重要特征的权重压缩到零
- 随机森林重要性:构建多棵决策树,评估每个特征的平均贡献
- 梯度提升:通过序列模型训练,识别最能改善结果的特征
嵌入方法就像是厨师一边烹饪一边调整配料,省时又高效。
非监督学习的特征选择
在非监督学习中,我们没有目标变量,特征选择就需要其他方法:
- 主成分分析(PCA):将可能相关的变量转换为线性不相关的主成分
- 独立成分分析(ICA):将多变量数据分离为独立的组件
- 自编码器:神经网络的一种,学习数据的压缩表示

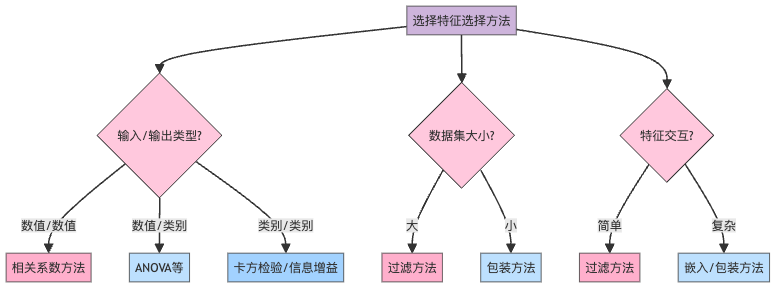
如何选择合适的特征选择方法?
选择合适的特征选择方法,就像是选择合适的工具修理不同的物品。考虑因素包括:
- 输入和输出变量的性质:
- 数值输入、数值输出:回归问题,适合皮尔逊相关系数
- 数值输入、类别输出:分类问题,适合ANOVA或肯德尔系数
- 类别输入、类别输出:分类问题,适合卡方检验或信息增益
- 数据集大小和特征空间:大数据集适合快速的过滤方法
- 特征复杂度:特征间有复杂交互时,包装方法或嵌入方法更合适
- 模型类型:不同模型适合不同的特征选择方法
实战建议:从科学到艺术
特征选择既是科学也是艺术。这里有一些实用建议:
- 结合领域知识:了解你的数据背景,有些看似不重要的特征可能在特定领域很关键
- 多方法结合:不同方法有不同优势,组合使用往往效果更好
- 交叉验证:通过交叉验证评估特征子集的泛化能力
- 注意特征工程:有时创造新特征比选择现有特征更有效
- 平衡简洁与性能:模型越简单越好维护,但不要为了简洁牺牲太多性能
结语:特征选择的艺术
特征选择就像厨师选择食材、裁缝选择面料一样,需要经验和技巧。掌握这门”瘦身术”,你的AI模型将更加高效、准确且易于理解。
下次当你面对一个复杂的数据集时,别忘了问自己:”我真的需要所有这些特征吗?”——这可能是提升模型性能的第一步。
记住,在机器学习中,有时”少即是多”!