
想象一下这个场景:你正在开发一个识别垃圾邮件的模型,但你的数据集中99%都是正常邮件,只有1%是垃圾邮件。这时,即使你的模型简单地预测”所有邮件都是正常的”,它的准确率也能达到99%!听起来不错?实际上这是场灾难——因为你的模型根本没学到如何识别垃圾邮件。
这就是数据不平衡问题,它就像一个偏心的天平,让机器学习模型很难公正地学习。今天,我们要介绍一个强大的”天平调节器”——imbalanced-learn库,它能帮你重新平衡数据,让模型不再偏心。
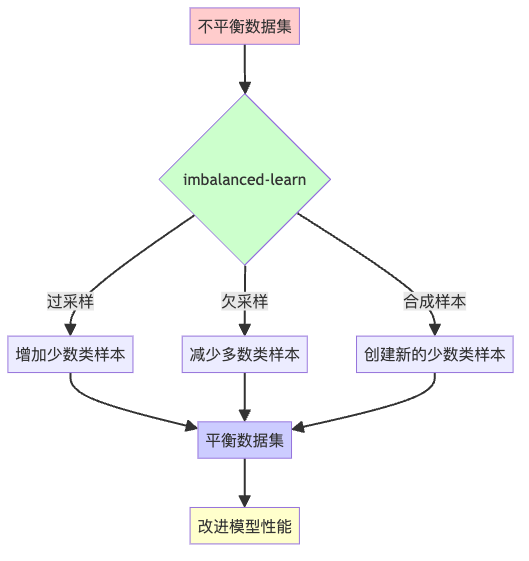
为什么数据不平衡是个大问题?
在现实世界中,不平衡数据比比皆是:
- 信用卡欺诈检测(99.9%是正常交易)
- 疾病诊断(大多数人是健康的)
- 设备故障预测(设备大部分时间正常运行)
当你的模型面对这些不平衡数据时,它会像个偏心的裁判,对多数类情有独钟,而忽视少数类——即使少数类往往是我们更关心的(比如欺诈交易)。
imbalanced-learn:数据平衡的四大法宝
Python的imbalanced-learn库(简称imblearn)提供了多种解决数据不平衡的技术。下面介绍四种最常用的方法,我保证,看完后你会觉得处理不平衡数据简直就是小菜一碟!
1. 随机过采样(Random Over-sampling):复制少数派
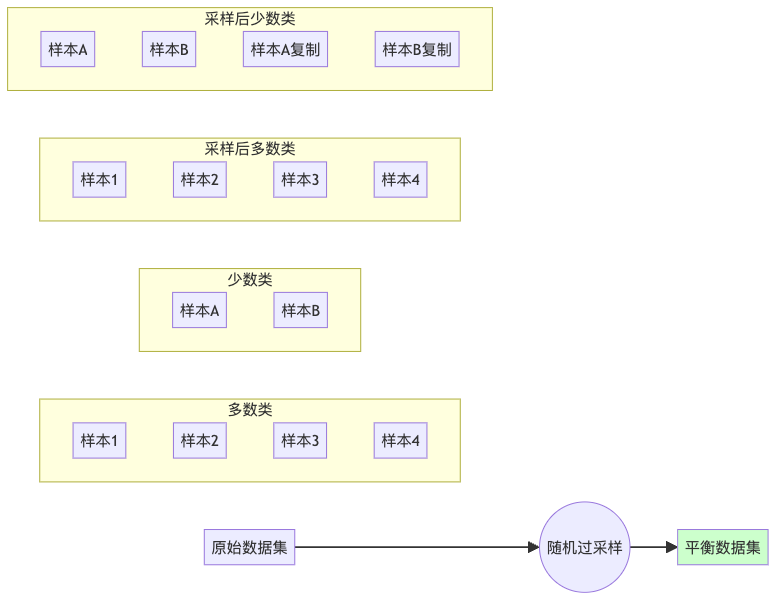
随机过采样就像是给少数派开小灶,通过复制少数类样本来增加它们的数量,直到达到与多数类的平衡。
from imblearn.over_sampling import RandomOverSampler
# 创建过采样器
ros = RandomOverSampler(random_state=42)
# 应用过采样
X_resampled, y_resampled = ros.fit_resample(X, y)随机过采样的优点是简单高效,但缺点是可能导致过拟合,因为它只是简单地复制了现有样本,没有带来新信息。
2. 随机欠采样(Random Under-sampling):削减多数派
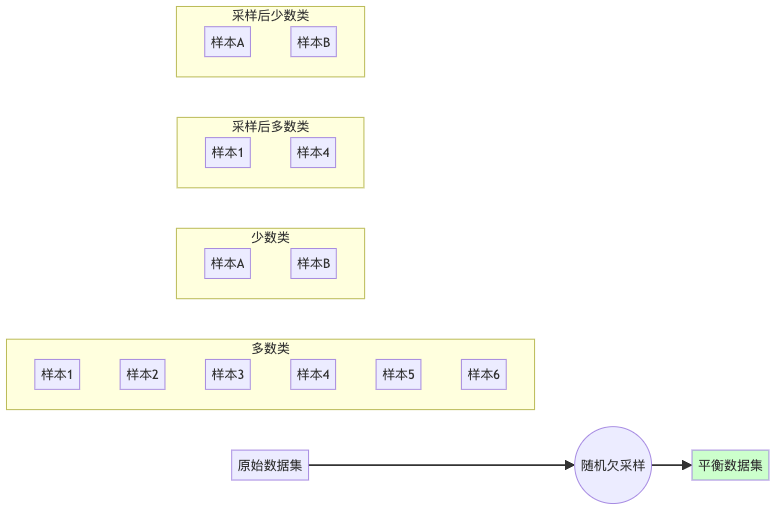
随机欠采样则采取了相反的策略——削减多数类样本,直到两类样本数量相当。这就像是给富人征税,拉近贫富差距。
from imblearn.under_sampling import RandomUnderSampler
# 创建欠采样器
rus = RandomUnderSampler(random_state=42)
# 应用欠采样
X_resampled, y_resampled = rus.fit_resample(X, y)这种方法的优点是简单且能减少训练时间,但可能会丢失多数类中的重要信息。
3. SMOTE(Synthetic Minority Over-sampling Technique):合成少数派
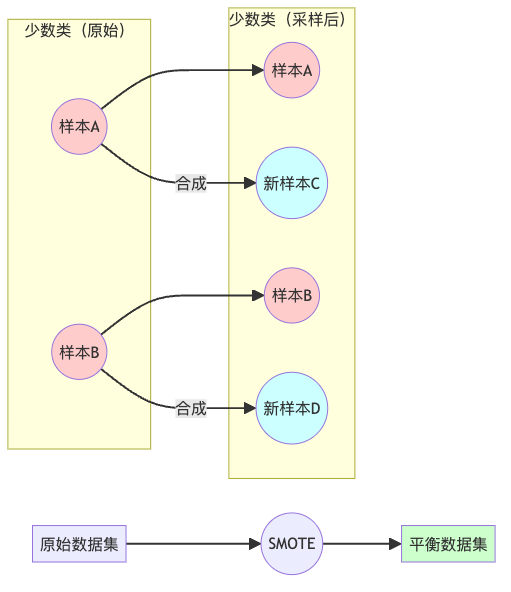
SMOTE不是简单地复制少数类样本,而是通过在少数类样本之间插值来创建新的合成样本。这就像是DNA重组,创造出新的生命形式!
from imblearn.over_sampling import SMOTE
# 创建SMOTE采样器
smote = SMOTE(random_state=42)
# 应用SMOTE
X_resampled, y_resampled = smote.fit_resample(X, y)SMOTE的优点是生成的新样本具有一定的多样性,减少了过拟合的风险,但在高维空间中可能会生成不现实的样本。
4. ADASYN(Adaptive Synthetic Sampling):智能合成少数派
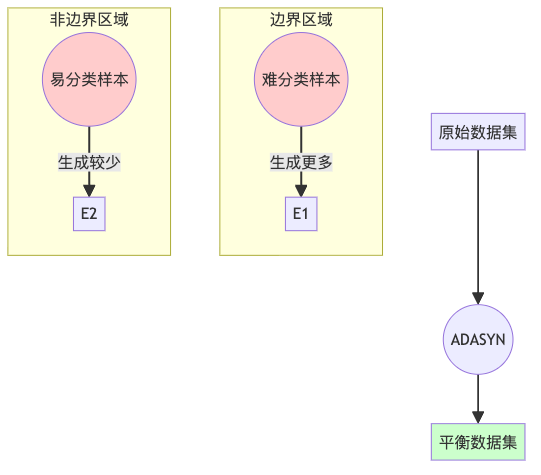
ADASYN是SMOTE的进阶版,它更关注那些难以分类的少数类样本。就像是给学习困难的学生提供更多的辅导,让他们能跟上大部队。
from imblearn.over_sampling import ADASYN
# 创建ADASYN采样器
adasyn = ADASYN(random_state=42)
# 应用ADASYN
X_resampled, y_resampled = adasyn.fit_resample(X, y)ADASYN的优点是能更好地关注决策边界附近的困难样本,提高分类器在这些区域的性能。
选择正确的武器:如何选择合适的采样方法?
面对这么多选择,你可能会感到困惑。这里有一些简单的指南:
- 数据集很小:尝试随机过采样或SMOTE,避免丢失信息
- 数据集很大:可以考虑随机欠采样,节省计算资源
- 少数类非常稀少:SMOTE或ADASYN通常比随机过采样效果更好
- 类别严重不平衡:可以组合使用过采样和欠采样方法
- 决策边界复杂:ADASYN可能会有更好的表现
实战示例:拯救不平衡数据集
让我们看一个简单的例子,如何使用imbalanced-learn库处理不平衡数据:
# 导入必要的库
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
# 创建一个不平衡的数据集
X, y = make_classification(n_samples=5000, n_classes=2, weights=[0.9, 0.1],
n_features=20, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用原始不平衡数据训练模型
clf_original = RandomForestClassifier(random_state=42)
clf_original.fit(X_train, y_train)
y_pred_original = clf_original.predict(X_test)
print("不平衡数据的分类结果:")
print(classification_report(y_test, y_pred_original))
# 使用SMOTE平衡数据
smote = SMOTE(random_state=42)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
# 使用平衡后的数据训练模型
clf_balanced = RandomForestClassifier(random_state=42)
clf_balanced.fit(X_train_resampled, y_train_resampled)
y_pred_balanced = clf_balanced.predict(X_test)
print("\n平衡数据后的分类结果:")
print(classification_report(y_test, y_pred_balanced))在这个例子中,你会发现使用SMOTE处理后的数据训练出的模型,在少数类上的性能会有显著提升,尤其是在召回率(Recall)方面。
总结:平衡之道
在机器学习中,数据不平衡就像是一个隐形杀手,悄悄地影响着你模型的性能。imbalanced-learn库提供了一系列强大的工具来对抗这个问题:
- 随机过采样:简单复制少数类样本
- 随机欠采样:随机删除多数类样本
- SMOTE:生成合成的少数类样本
- ADASYN:智能地生成更多难分类的少数类样本
记住,没有一种方法是万能的,最好的做法是尝试多种方法,并根据你的具体问题选择最合适的一种或组合多种方法。
数据平衡只是提高模型性能的一个方面,它应该与其他技术(如特征工程、模型选择、参数调优等)结合使用,才能发挥最大效果。
现在,你已经掌握了对抗数据不平衡的利器,是时候让你的模型更公平、更准确地看待这个不平衡的世界了!