大型语言模型 (LLM) 已经展现出令人印象深刻的文本理解能力。但在很多情况下,我们希望 LLM 能够理解的不仅仅是文本。我们可能希望它们接收或生成多种模式的数据,如文本、图像和音频。具有此功能的 LLM 称为多模态 LLM,在本文中,我们将对视觉语言领域的三种多模态 LLM 进行概述。正如我们所见,这三种 LLM 都具有以下共同的组件:
- 仅有视觉的模型。
- 纯文本模型(LLM)。
- 一个或多个组件,将视觉模型的输出转换为可以输入到 LLM 的格式。
让我们开始吧。
Flamingo 火烈鸟
Flamingo是一门多模态大型语言模型 (LLM),于 2022 年推出。视觉和语言组件的工作原理如下:
- 视觉编码器将图像或视频转换为嵌入(数字列表)。这些嵌入的大小取决于输入图像的尺寸或输入视频的长度,因此另一个称为感知器重采样器的组件将这些嵌入转换为通用的固定长度。
- 语言模型接收文本和来自 Percever Resampler 的固定长度视觉嵌入。视觉嵌入用于多个“交叉注意力”块,这些块学习根据当前文本权衡视觉嵌入不同部分的重要性。
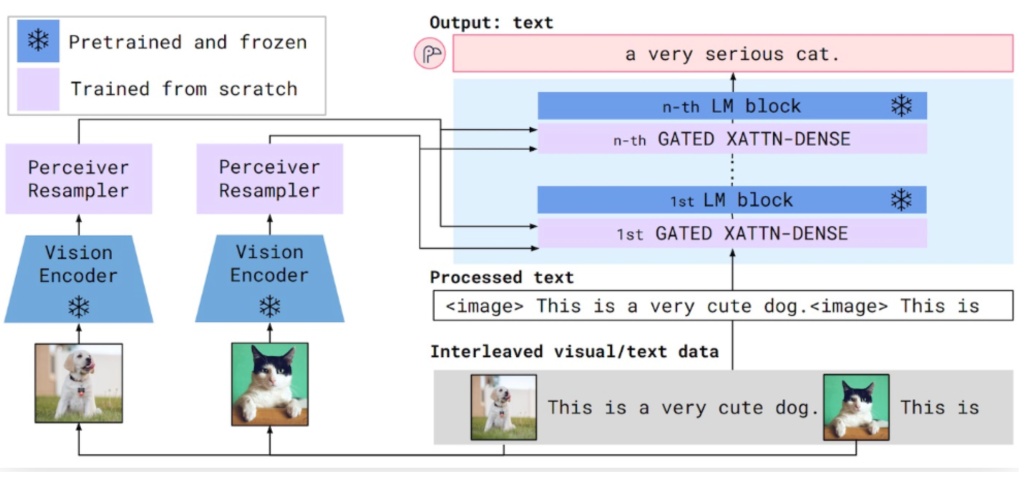
训练分为三个步骤:
- 视觉编码器使用 CLIP 进行预训练。CLIP 实际上同时训练视觉编码器和文本编码器,因此此步骤中的文本编码器将被丢弃。
- 该语言模型是一个预先训练了下一个标记预测的Chinchilla模型,即根据一系列先前的字符预测下一组字符。大多数 LLM(如 GPT-4)都是这样训练的。您可能会听到这种类型的模型被称为“自回归”,这意味着该模型根据过去的值预测未来的值。
- 在第三阶段,将未经训练的交叉注意力模块插入语言模型中,并在视觉编码器和语言模型之间插入未经训练的感知器重采样器。这是完整的 Flamingo 模型,但交叉注意力模块和感知器重采样器仍需要训练。为此,整个 Flamingo 模型用于计算下一个标记预测任务中的标记,但输入现在包含与文本交错的图像。此外,视觉编码器和语言模型的权重被冻结。换句话说,只有感知器重采样器和交叉注意力模块实际上得到更新和训练。
经过训练,Flamingo 能够执行各种视觉语言任务,包括以对话形式回答有关图像的问题。

什么是 CLIP?
如上一节所述,Flamingo 在预训练阶段使用 CLIP。CLIP不是多模态 LLM。相反,它是一种训练方法,可以生成具有强大下游功能的独立视觉和文本模型。CLIP 代表对比语言图像预训练,其概念非常简单:
- 该模型架构由图像编码器和文本编码器组成。图像编码器将图像转换为嵌入(数字列表),文本编码器将文本转换为嵌入。
- 这两个编码器在成批的图像-文本对上进行训练,其中文本描述图像。编码器的训练方式如下:
- 对于每个图像-文本对,图像和文本嵌入彼此“接近”。
- 对于所有不匹配的图像-文本对,图像和文本嵌入彼此相距甚远。
注意,有很多种方法可以测量两个嵌入之间的距离。一些常用的方法是欧几里得距离和余弦相似度。CLIP 使用后者。
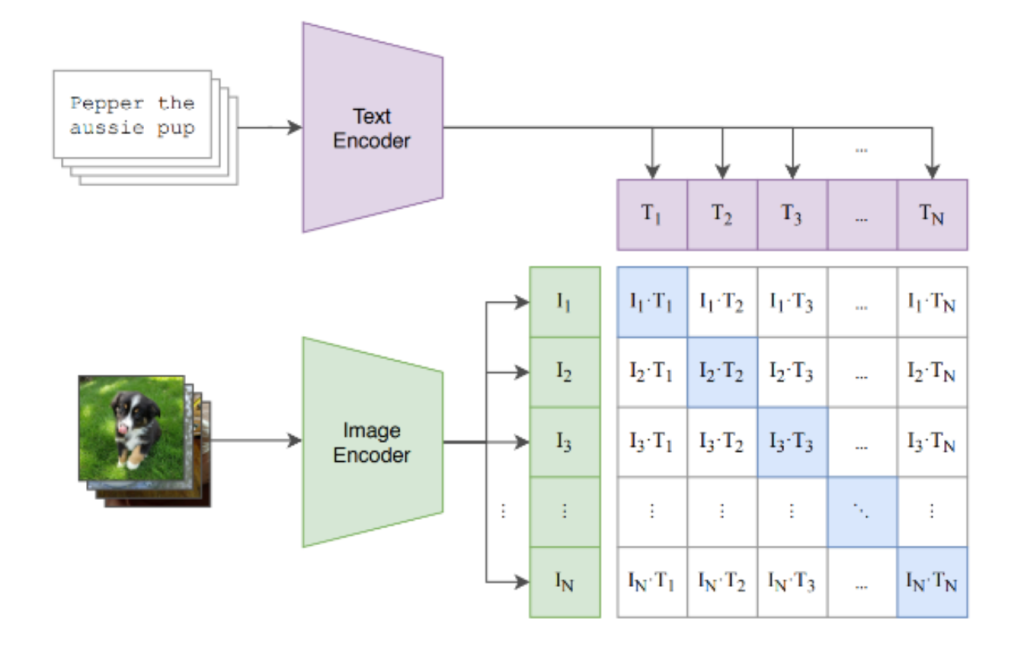
此图中有 N 个图像-文本对。I N和 T N是第 N 个图像-文本对的图像和文本嵌入。突出显示的蓝色方块表示我们希望靠近的嵌入对。
从高层次来看,CLIP 学习的是联合图像-文本嵌入空间,这基本上意味着可以直接计算图像和文本之间的相似度。事实证明,以此为目标训练模型通常非常有用,包括在多模态 LLM 环境中。
BLIP-2
BLIP-2是一款多模态 LLM,于 2023 年初发布。与 Flamingo 一样,它包含预训练的图像编码器和 LLM。但与 Flamingo 不同的是,图像编码器和LLM 均未受影响(预训练后)。
为了将图像编码器连接到 LLM,BLIP-2 使用“Q-Former”,它由两个组件组成:
- 视觉组件接收一组可学习的嵌入和冻结图像编码器的输出。与 Flamingo 中所做的一样,图像嵌入被输入到交叉注意层中。
- 文本组件接收文本。
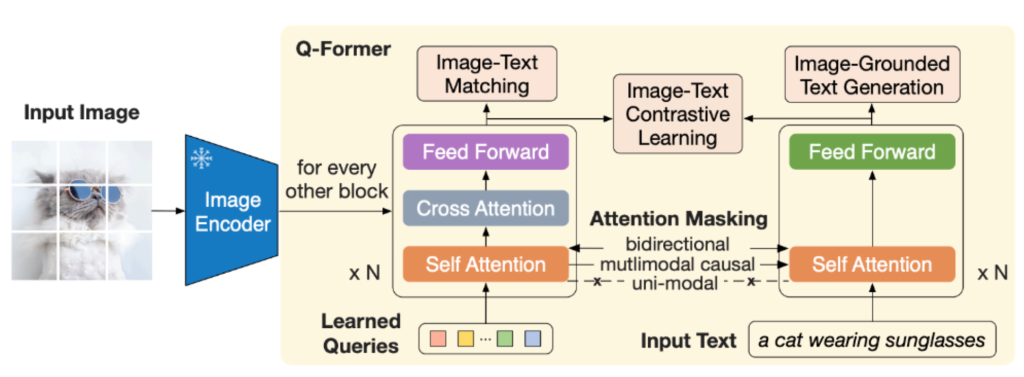
摘自 BLIP-2 论文,展示了 Q-Former 的内部结构及其训练目标。
BLIP-2 训练分为两个阶段:
- 在第 1 阶段,Q-Former 的两个组件针对三个目标进行训练,这些目标实际上源自BLIP-1论文:
- 图像-文本对比学习(类似于 CLIP,但有一些细微的差别)。
- 基于图像的文本生成(生成图像的标题)。
- 图像-文本匹配(二元分类任务,其中对于每个图像-文本对,模型必须回答 1 来表示匹配,否则回答 0)。
- 在第 2 阶段,通过在 Q-Former 和 LLM 之间插入投影层来构建完整模型。此投影层将 Q-Former 的嵌入转换为具有与 LLM 兼容的长度。然后,完整模型负责描述输入图像。在此阶段,图像编码器和 LLM 保持冻结状态,并且仅训练 Q-Former 和投影层。

图片摘自 BLIP-2 论文,展示了完整的模型架构。投影层标记为“完全连接”。
在论文的实验中,他们使用 CLIP 预训练的图像编码器和OPT或Flan-T5作为 LLM。实验表明,BLIP-2 在各种视觉问答任务上的表现都优于 Flamingo,但可训练参数却少得多。这使得训练过程更加轻松,且更具成本效益。
LLaVA
LLaVA是一门多模态 LLM,于 2023 年发布。其架构非常简单:
- 视觉编码器使用 CLIP 进行预训练。
- LLM 是经过预先训练的Vicuna模型。
- 视觉编码器通过单个投影层连接到 LLM。
请注意,与 BLIP-2 中的 Q-Former 以及 Flamingo 中的感知器重采样器和交叉注意层相比,视觉编码器和 LLM 之间的组件非常简单。
训练分为两个阶段:
- 在第 1 阶段,训练目标是图像字幕。视觉编码器和 LLM 被冻结,因此只训练投影层。
- 在第 2 阶段,LLM 和投影层在部分合成的指令跟踪数据集上进行微调。它是部分合成的,因为它是在 GPT-4 的帮助下生成的。

图片来自 LLaVA 论文,展示了完整的模型架构。 作者对 LLaVA 的评价如下:
- 他们使用 GPT-4 来评估 LLaVA 在部分合成数据集上的响应质量。在这里,LLaVA 相对于 GPT-4 的得分为 85%。
- 他们在名为 ScienceQA 的视觉问答数据集上使用标准评估指标。在这里,经过微调的 LLaVA 表现优于 GPT-4。
LLaVA 说明,简单的架构在使用部分合成数据进行训练时可以取得优异的结果。
在这篇文章中,我们简要介绍了三个重要的多模态 LLM 以及 CLIP。