
嘿,各位极客们!今天我们要聊一个在机器学习界可以说是”网红”般存在的算法 —— XGBoost。它不仅在 Kaggle 比赛中频频登顶,还在工业界广受欢迎。如果你问为什么,那就需要从头说起了。
XGBoost 是什么?
想象一下,如果把机器学习算法比作武林高手,那么 XGBoost 就是一位集速度与智慧于一身的”大侠”。它的全名是 eXtreme Gradient Boosting(极限梯度提升),是由华盛顿大学的陈天奇开发的一个开源机器学习库。
为什么要用 XGBoost?
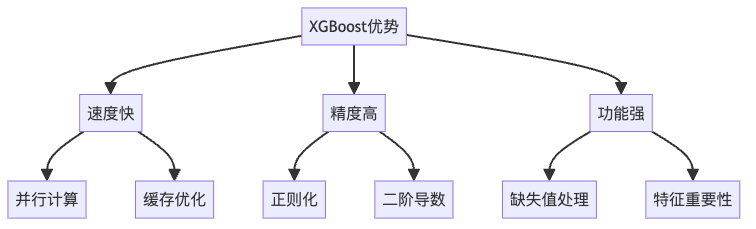
如果说传统的机器学习算法是普通汽车,那么 XGBoost 就是一辆配备了各种黑科技的”超跑”。它的特点包括:
- 🚀 极速性能:
- 支持并行计算
- 使用缓存优化策略
- 可以处理数十亿级别的数据
- 🛡️ 内置防护:
- 自带正则化功能,就像给模型装了个”防过拟合护盾”
- 优雅处理缺失值,不用你操心数据清洗的烦恼
- 🎯 精准度高:
- 比普通梯度提升树表现更好
- 在各大数据科学竞赛中屡创佳绩
XGBoost 如何工作?
让我们用一个简单的比喻来理解 XGBoost 的工作原理:想象你在玩一个射击游戏,第一次射击可能偏离靶心很远(这就是第一个弱学习器)。但是不要灰心,你可以根据这次的偏差,调整下一次射击的位置。每一次射击都会让你离目标更近一些,直到最后能够精准命中靶心。
实战准备
在实际使用 XGBoost 之前,你需要:
- 数据预处理:
# 将数据转换为 XGBoost 专用的 DMatrix 格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)- 参数调优:
就像调试游戏中的武器属性一样,XGBoost 也有一些关键参数需要调整:
参数详解
- learning_rate(学习率):
- 就像游戏中的移动速度
- 值越小,学习越谨慎,但需要更多轮次
- 值越大,学习越激进,但可能会”翻车”
- max_depth(最大深度):
- 决策树的最大深度
- 类似于你思考问题时的决策层数
- 太深容易”想太多”(过拟合)
- 太浅可能”想得太简单”(欠拟合)
- n_estimators(树的数量):
- 就像你要射击多少次
- 数量要适中,太多会浪费时间
- 太少可能达不到好效果
实际应用场景
XGBoost 在实际中的应用非常广泛,比如:
- 🎯 广告点击率预测
- 预测用户是否会点击广告
- 帮助投放更精准的广告
- 📈 股票市场预测
- 分析历史数据预测股价走势
- 识别市场潜在风险
- 🏪 销售预测
- 预测商店未来销售额
- 优化库存管理
- 🦠 疾病预测
- 基于症状预测疾病风险
- 辅助医生诊断
XGBoost vs 其他算法
如果把机器学习算法比作武林高手,那么:
- AdaBoost:武林前辈,开创了 Boosting 流派
- CatBoost:擅长处理类别特征的新生代高手
- LightGBM:微软出品的轻量级选手
- XGBoost:集大成者,各方面都很均衡
小贴士
- 🎯 调参建议:
- 先用默认参数跑通流程
- 再逐步调整关键参数
- 使用交叉验证避免过拟合
- 💡 性能优化:
- 对于大数据集,考虑使用 GPU 加速
- 合理设置 early_stopping_rounds 避免无效训练
- 🛠️ 实战技巧:
- 特征工程很重要
- 定期备份最佳模型
- 监控验证集表现
结语
XGBoost 就像一把”倚天剑”,威力强大,但要发挥它的威力,需要不断练习和调优。希望这篇文章能帮助你更好地理解和使用 XGBoost。记住,在机器学习的江湖中,工具固然重要,但更重要的是如何运用它来解决实际问题。
好了,各位极客,准备好开始你的 XGBoost 之旅了吗?让我们一起在数据科学的江湖中开创属于自己的传奇吧!