
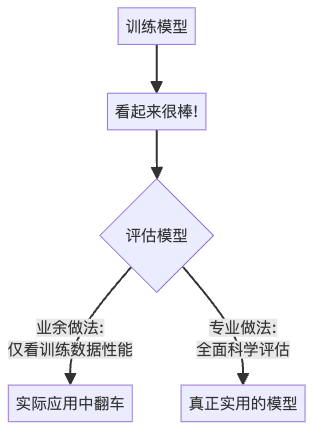
嘿,AI探险家们!你是否曾经花了好几周训练了一个”完美”的模型,却发现它在实际应用中表现得像个”学渣”?别担心,我们都经历过这种痛苦。事实上,这正是业余AI实践者和专业人士之间的重要分水岭——专业人士知道,评估模型不能只看它在训练数据上多么优秀,而是需要一套科学的”成绩单”来衡量它在未知数据上的真实表现。
今天,我们就来聊聊这些模型评估指标——它们是区分业余与专业AI模型的关键标准,也是你判断模型是否真正”聪明”的必备工具!
模型评估:为什么如此重要?
想象一下,你训练了一个预测明天股票价格的模型。模型自信地说:”买入!明天股票肯定涨!”于是你把积蓄全部投入,结果第二天…股票暴跌了!💸 这就是为什么我们需要严格的模型评估。
数据划分:评估的基础
在讨论具体指标前,我们需要先了解数据划分的重要性。评估模型不能用训练过的数据,这就像用教科书里的例题测试学生——当然会得高分,但并不能证明他真的学会了。
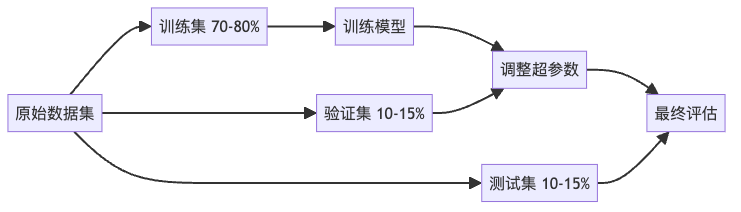
- 训练集:模型的”教材”,用来学习模式和关系
- 验证集:模型的”练习题”,用来调整模型参数
- 测试集:模型的”期末考试”,用来评估最终性能
机器学习模型类型概览
在深入评估指标之前,让我们先了解本文将要讨论的三种主要模型类型:
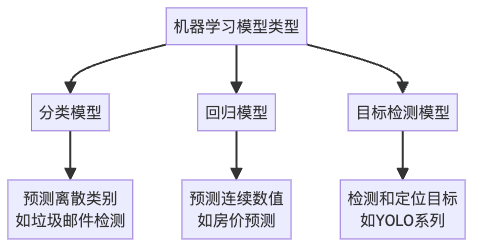
- 分类模型:将输入数据分配到预定义的类别中。例如,判断邮件是否为垃圾邮件,识别图像中的动物种类等。这些模型的输出是离散的类别标签。
- 回归模型:预测连续的数值。例如,预测房价、股票价格、温度等。这些模型的输出是连续的数值。
- 目标检测模型:不仅需要识别图像中存在的对象类别,还需要定位它们的位置。例如,自动驾驶系统中识别和定位行人、车辆等。
每种模型类型都有其特定的评估指标,让我们逐一了解。
分类模型评估指标
分类模型尝试将数据分到不同的类别中,比如猫/狗、垃圾邮件/正常邮件等。以下是评估这类模型的主要指标:
1. 混淆矩阵:一切的基础
混淆矩阵是评估分类模型最基础的工具,它像一张详细的”成绩单”,记录了模型的各种预测情况。
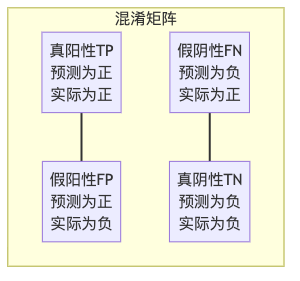
举个例子,假设我们训练了一个猫狗识别器,结果如下:
- 90只猫被正确识别为猫(TP)
- 10只狗被错误识别为猫(FP)
- 5只猫被错误识别为狗(FN)
- 95只狗被正确识别为狗(TN)
从混淆矩阵,我们可以计算多个重要指标:
- 准确率(Accuracy) = (TP + TN) / 总样本数 = (90 + 95) / 200 = 92.5%
- 精确率(Precision) = TP / (TP + FP) = 90 / 100 = 90%(在所有预测为”猫”的结果中,实际是猫的比例)
- 召回率(Recall) = TP / (TP + FN) = 90 / 95 = 94.7%(在所有实际是猫的样本中,被正确识别的比例)
- 特异性(Specificity) = TN / (TN + FP) = 95 / 105 = 90.5%(在所有实际是狗的样本中,被正确识别的比例)
不同场景下,这些指标的重要性不同。比如在癌症诊断中,召回率更重要(宁可误诊,不能漏诊);而在垃圾邮件过滤中,精确率更重要(宁可漏过一些垃圾邮件,也不能误删重要邮件)。
2. F1分数:精确率和召回率的平衡
在很多情况下,我们需要同时考虑精确率和召回率,这就是F1分数的用武之地。
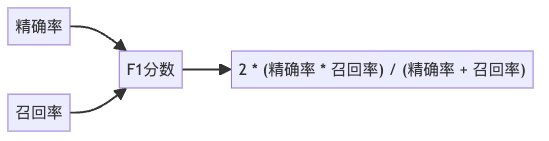
F1分数是精确率和召回率的调和平均值,比算术平均更合理。为什么?想象一个模型的精确率为0,召回率为1(即把所有样本都预测为正类)。算术平均会给出0.5的分数,看起来还不错;而调和平均则会给出0,这才真实反映了模型毫无用处的事实。
更进一步,当我们需要对精确率或召回率赋予不同权重时,可以使用F-beta分数:
- β < 1:更看重精确率(减少假阳性)
- β > 1:更看重召回率(减少假阴性)
3. ROC曲线和AUC:全面的性能评估
ROC曲线是评估二分类模型的强大工具,它展示了不同决策阈值下真阳性率(TPR,即召回率)与假阳性率(FPR)的关系。这是专业AI工程师必备的评估工具,而业余爱好者往往忽略它的重要性。

AUC(Area Under Curve)是ROC曲线下的面积,范围从0.5(随机猜测)到1(完美分类):
- 0.9-1.0:优秀(A级)- 专业水平模型通常在此区间
- 0.8-0.9:良好(B级)
- 0.7-0.8:一般(C级)- 许多业余模型停留在此区间
- 0.6-0.7:较差(D级)
- 0.5-0.6:不及格(F级)
AUC的一大优势是它不受样本不平衡的影响,适合评估各种分类场景。专业AI团队会关注曲线的形状和在不同操作点的表现,而不仅仅是单一数值。
4. 对数损失(Log Loss):概率预测的质量
对数损失衡量的是预测概率的质量,而不仅是最终分类的正确性。它对预测错误且信心高的情况惩罚更为严重。
例如,如果模型以90%的置信度做出了错误的预测,对数损失会给予比以51%置信度做出同样错误预测更严厉的惩罚。这使得对数损失特别适合需要可靠概率输出的应用,如风险评估或医疗诊断。
回归模型评估指标
回归模型预测连续值,比如房价、温度或股票价格。以下是评估这类模型的主要指标:
1. 均方误差(MSE)和均方根误差(RMSE)

MSE和RMSE是回归模型最常用的评估指标。RMSE的优势在于它与原始数据单位相同,更容易解释。例如,如果我们预测房价,RMSE=50,000意味着我们的预测平均误差约为5万元。
这两个指标的特点是对大误差进行更严厉的惩罚(因为平方操作)。如果你的数据中有异常值,它们会对MSE和RMSE产生很大影响。
2. 平均绝对误差(MAE)
如果你想对所有误差一视同仁,不论大小,可以使用MAE。它计算预测值与实际值之间绝对差值的平均值,对异常值不如MSE敏感。
3. R方(R²):与基准模型的比较
单看RMSE或MAE,很难判断模型好坏,因为我们不知道这个误差相对于数据的波动性意味着什么。R方解决了这个问题:
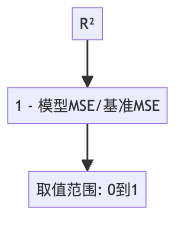
R方告诉我们,相比于简单地预测均值,我们的模型解释了多少数据变异。R方值在0到1之间:
- 1表示完美预测
- 0表示模型不比预测均值好
- 负值表示模型比预测均值还差
不过,R方有个问题:添加任何新特征都会使R方保持或增加,即使这些特征毫无意义。这就是为什么我们有”调整R方”,它会根据特征数量进行修正,惩罚无用特征的添加。
目标检测模型评估指标
目标检测模型(如YOLO系列)不仅需要判断对象的存在和类别,还需要准确定位它们的位置。评估这类模型需要特殊的指标:
1. 交并比(IoU):边界框的重叠度量
的计算方法.png)
IoU衡量预测边界框与实际边界框的重叠程度。值越高(接近1)表示定位越准确。不同的应用可能需要不同的IoU阈值来判定检测是否成功。
2. 平均精度(AP)和平均精度均值(mAP)
AP是针对单个类别的检测性能指标,而mAP是所有类别AP的平均值,是目标检测中最常用的综合评估指标。
在计算AP和mAP时,我们通常会考虑不同的IoU阈值:
- mAP@.5:IoU阈值为0.5时的mAP
- mAP@.5:.95:IoU从0.5到0.95(步长0.05)的平均mAP
此外,对于实时应用,我们还需要考虑速度指标,如每秒帧数(FPS)。
交叉验证:防止过拟合的利器
到目前为止,我们讨论的指标都是在单一的训练/测试分割上计算的。但这可能导致我们的评估受到特定分割的影响。交叉验证通过多次不同的分割来解决这个问题。这是区分业余和专业AI实践者的另一个关键点——专业人士总是使用交叉验证!

想象一个真实案例:我曾参加一个数据科学比赛,公共排行榜上表现最差的模型在最终的私有排行榜上表现最好!这就是过拟合的典型例子——模型过度适应了公共测试集,但在新数据上表现不佳。交叉验证能帮助我们发现并避免这种情况。
k的选择是一个权衡:
- 小k:选择偏差大,但方差小
- 大k:选择偏差小,但方差大
通常,k=10是一个不错的选择。专业团队会根据数据集大小和计算资源进行合理选择,而不是随意决定。
模型评估的生命周期
评估不是训练后的一次性活动,而是贯穿整个模型开发生命周期的持续过程。

- 训练期间:监控评估指标变化,了解学习进度和潜在问题
- 验证阶段:使用独立验证集评估和调整模型
- 测试阶段:使用完全未见过的测试集进行最终评估
- 部署后:持续监控模型在实际环境中的表现
其他机器学习模型类型及评估指标
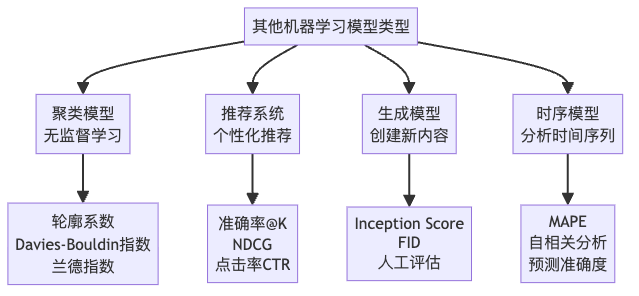
除了上述三种主要模型类型外,机器学习领域还有许多其他类型的模型,每种都有其特定的评估方法:
实践建议:选择合适的评估指标
选择正确的评估指标取决于你的问题类型、数据特性和业务目标。以下是一些建议:
- 了解业务目标:什么样的错误成本更高?假阳性还是假阴性?
- 考虑数据分布:数据是否平衡?如果不平衡,准确率可能会产生误导。
- 使用多种指标:单一指标可能无法全面反映模型性能。
- 可视化结果:除了数值指标,直观查看预测结果也很重要。
- 考虑计算复杂性:某些指标计算可能很耗时,特别是对大型数据集。
总结
评估指标是机器学习过程中不可或缺的一部分,它们不仅告诉我们模型的性能如何,还指导我们改进的方向。现在,让我们明确总结业余AI与专业AI在评估方面的关键区别:
| 方面 | 业余AI实践者 | 专业AI实践者 |
|---|---|---|
| 评估指标选择 | 过分依赖单一指标(通常是准确率) | 使用多种互补的评估指标 |
| 数据使用方式 | 主要在训练数据上评估性能 | 严格区分训练集、验证集和测试集 |
| 交叉验证应用 | 很少或不正确使用交叉验证 | 系统性应用交叉验证防止过拟合 |
| 业务目标关联 | 忽略数据分布不平衡的影响 | 根据业务目标选择合适的评估标准 |
| 评估融入流程 | 未将模型评估融入开发生命周期 | 实施持续评估,贯穿模型的整个生命周期 |
记住:在训练集上表现良好不代表在实际应用中也会表现良好。这是业余与专业的本质区别。
下次当有人问你”你的模型有多好?”时,不要只回答”准确率95%!”,而是根据具体问题给出全面的评估结果。因为在AI的世界里,专业人士知道成绩单比单一分数更重要!