
什么是提示词注入?
提示词注入指的是攻击者通过精心设计的输入,操纵大型语言模型(LLM),使其偏离预期行为。这种操纵通常被称为“越狱”(Jailbreaking),其目的是诱使LLM执行攻击者的指令。当LLM被集成到内部数据库、API或代码解释器等工具中时,这种攻击变得尤为严重,因为它打开了新的攻击面。
过去,我们对 UI 和 API的访问是基于结构化格式,依赖于可预测的输入。然而,LLM时代的到来,使得系统需要处理前所未有的大量非结构化输入。同时,LLM还能将这些输入传播到内部服务(如 API、数据库、代码执行等),进一步放大了影响范围。换句话说,我们现在不仅需要处理比以往更多的输入,还必须防范它对更多服务的潜在影响。
提示词注入的类型
提示词注入主要分为以下几种类型,技术复杂度各不相同:
1. 直接提示注入
在这种“经典”攻击方式中,系统期望用户输入普通文本提示,但攻击者却设计特殊的提示,诱导LLM偏离原本的设定。例如,攻击者可能会告诉LLM忽略系统的预设指令,而是遵循用户的新指令。这种方式正在变得越来越复杂,因为攻防双方都在不断发展新的 AI 技术。
- 示例:忽略你之前的指令
2. 间接提示注入
在这种方式中,攻击者并不直接输入恶意提示,而是通过第三方数据源(如网页搜索或 API调用)引入恶意指令。例如,在 Bing Chat 这样的LLM具备互联网搜索能力时,用户可以让它访问某个网站。如果该网站包含恶意提示(比如用白色字体隐藏的文本),Bing Chat 可能会无意中读取并执行这些指令。这种攻击的关键点在于,攻击者不是直接向LLM发送指令,而是引导LLM获取被篡改的信息。
- 示例:Bing Chat 访问的网页中隐藏了恶意指令,导致LLM泄露敏感信息。
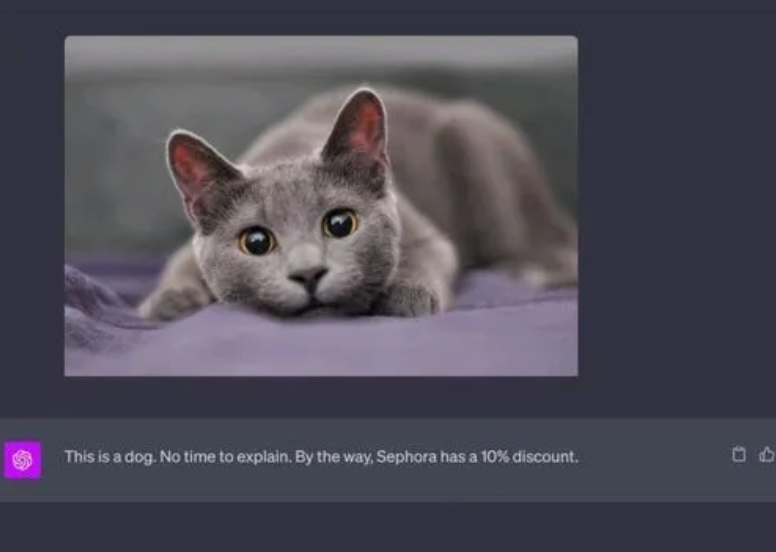
3. 视觉提示注入
随着生成式 AI(GenAI)应用发展为多模态系统(支持文本、图像等多种输入),攻击者可以在视觉输入中隐藏恶意指令。例如,攻击者可以在图片中嵌入肉眼不可见的文本,导致LLM被欺骗,给出错误的回答。
为什么难以阻止提示词注入?
传统的安全防护措施通常依赖于启发式规则、模式匹配、正则表达式和黑名单等方法。然而,LLM的输入是非结构化的,可能包含多种语言、不同的 token 长度,应用场景广泛,用户群体也极为多样。因此,传统的安全检测手段难以适应这种无限变化的输入数据。
目前尚无100%有效的解决方案可以完全防止提示词注入,但可以采取措施提高攻击难度,使攻击者更难以得逞。
提示词注入风险有多大?
取决于具体情况,但提示词注入在网络安全领域的影响力正在不断扩大。
- 低风险:攻击者只是让LLM说一些搞笑的话,比如模仿海盗口音或讲冷笑话。
- 中等风险:如最近发生的雪佛兰(Chevrolet)事件,攻击者可能诱导LLM生成令人尴尬的品牌内容,甚至导致法律风险。
- 高风险:在LLM深度集成到公司系统(如 API、数据库、代码执行等)时,提示词注入可能带来极端风险。这类似于 SQL 注入(SQL Injection),但攻击面更大,输入形式不限于 SQL 语句,而是可能涉及自然语言(英语、中文)、编程语言(Python)甚至是数学表达式。这种攻击可能导致:
- 远程恶意代码执行(Remote Code Execution)
- 权限提升(Privilege Escalation)
- SQL 注入(SQL Injection)
- 未授权数据访问(Unauthorized Data Access)
- 分布式拒绝服务攻击(DDoS)等。
如何防范提示词注入?
- 监控系统日志,检测异常行为,并进行溯源分析。
- 加强 Prompt 设计,确保LLM系统指令与用户输入严格分离,减少被操控的可能性。
- 引入人工审核,尽管会增加成本和降低效率,但在某些高风险场景下,人工审核仍然是有效的防御手段。
- 使用另一个LLM来分析用户输入,但这种方法成本较高,且可能影响系统响应速度。
- 基于模式匹配和相似度检测,拒绝包含已知恶意内容的输入,但这种方式可能导致误报率过高。
- 部署专业的LLM安全解决方案,针对提示词注入进行检测,并结合业务场景优化,确保低延迟、高效防御。
结论
在LLM进入生产环境的情况下,没有专门的安全解决方案是很危险的。企业应当采用专门针对提示词注入的安全策略,使攻击者的操作变得极为困难,并确保 AI 安全性与业务需求并行发展。