现有的 NLP BOT 解决方案(例如 Alexa、Google DialogFlow 等)正在使用 Amazon 或 Google 等的服务,这需要将数据传出场所。包括金融机构在内的企业对安全性非常挑剔,并且不太喜欢走出自己的场所来获取任何服务。他们坚持尽可能采用本地解决方案,而不将任何客户数据暴露给任何第三方应用程序或解决方案。我们是否有任何本地 NLP-Bot 解决方案可供选择?幸运的是,我们确实有廉价且非常专业的标准解决方案。
当我们谈论一些此类解决方案时,我们有很多疑问,例如它是否同时支持语音和文本?它支持多种语言吗?我们需要什么样的硬件来支持这样的解决方案?它支持哪些不同的渠道(电话、网络文本、网络语音等)?
有可用的行业标准解决方案(框架),它确实回答了所有上述问题 – Rasa。它有助于构建您的本地解决方案,并且框架的方法非常创新。
什么是Rasa?
Rasa 是一个开源框架,支持 NLP Bot 概念,并提供完全的灵活性来定制事物。下图是 Rasa 的架构图。我将更详细地解释每个组件,以便更好地理解完整的 Rasa。

主要有4个组件,即连接器模块、NLU模块、对话管理模块和NLG模块。
连接器模块
该模块有助于将 NLP Bot 框架与不同渠道(如 Web、Google Agent 和社交媒体(如 Facebook、Slack 等))连接。有一些现成的连接器可用,可用于快速集成。
NLU 组件
NLU 组件由多个子组件组成,它们在理解所说内容方面发挥着非常重要的作用。以下是 NLU 的一些组件
- 词向量源
- 特征器
- 意图分类器
- 分词器
- 实体提取器
词向量源
这是加载语言模型的位置,应在配置开始时指定。主要有两种——Mitie 和 Spacy。与 Spacy 相比,Mitie 用于小话语数据集。 Mitie 可能会在不久的将来被弃用,但它在小型数据集上表现良好。如果有数百个示例,训练模型会变得非常缓慢且耗时。
特征器
有不同的特征器,它们用于不同的目的,例如意图分类、实体提取等特征。 MitieFeaturizer、SpacyFeaturizers 创建意图分类的特征。 RegexFeaturizer 用于实体提取。
意图分类器
这些分类器(根据用户查询对意图进行分类)用于意图识别,并且可能会或可能不会接受来自特征器的输入。一些意图分类器还输出意图排名。 KeywordIntentClassifier、MitieIntentClassifier、skLearnIntentClassifier EmbeddingIntentClassifier 是其中一些示例。其中一些分类器需要 Tokenizer 和 Featurizer 作为完整设置的一部分。
分词器
这些标记生成器有助于验证 Mitie 实体提取器使用的标记。 WhitespaceTokenizer、JiebaTokenizer(专门用于中文)、MitieTokenizer、SpacyTokenizer 是一些可用的 Tokenizer。
实体提取器
该组件识别并列出所有实体(来自用户查询的参数)。一些实体提取器包括:MitieEntityExtractor、SpacyEntityExtractor、EntitySynonymMapper、CRFEntityExtractor 和 DucklingExtractor。
处理任何新消息时 NLU 涉及的步骤
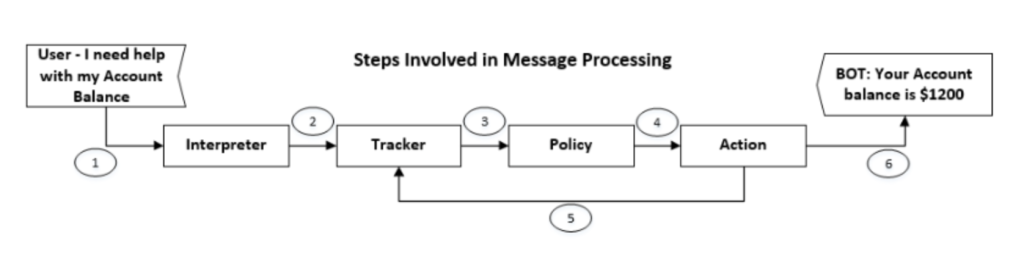
收到新消息后,它被传递到解释器,消息被转换为原始文本、意图和实体(槽)。这是 NLU 的一部分。 跟踪器有责任跟踪会话状态。策略接收 Tracker 的当前状态。策略决定下一步要采取什么操作,所选操作将记录到跟踪器中,并将响应发送给用户。 一旦确定了管道组件,就可以定义意图和实体以及训练数据 – 下图是典型的 Spacy 管道工作情况。

对话管理组件
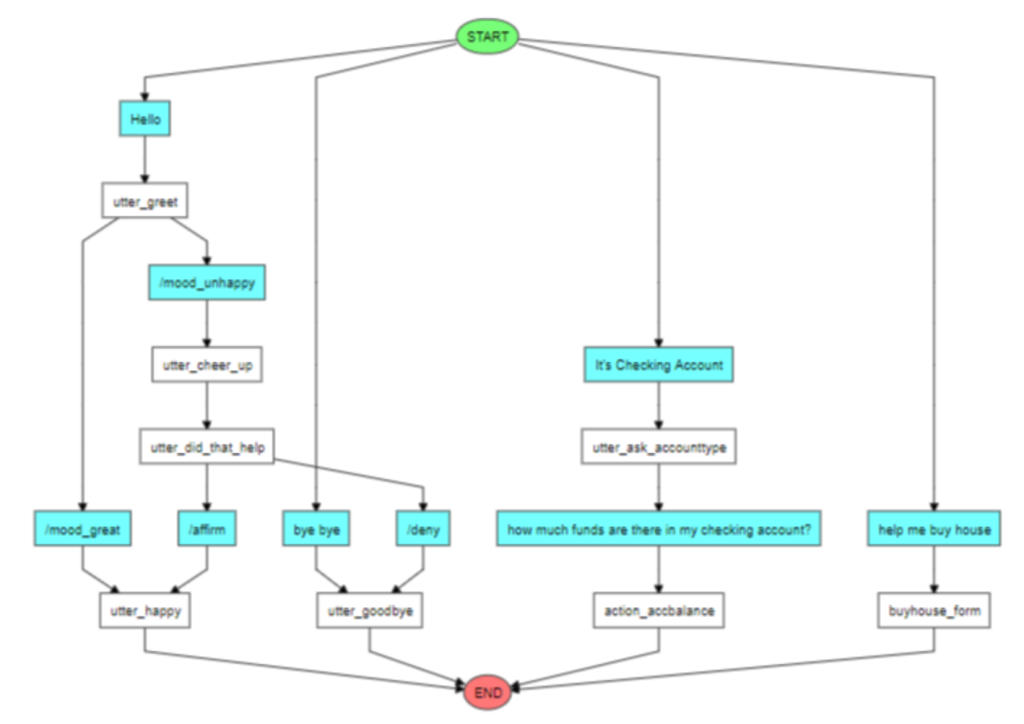
在此组件中,Rasa 根据其训练的对话管理模块决定下一步要采取的步骤(要调用的操作)。 Rasa 在内部根据其训练的对话管理创建流程图。下面是一个相同的例子。作为行动的一部分 – Rasa 可以连接 Web API,以从 Web 服务器获取更多数据。 下面给出了对话流程的示例图 –
NLG 模块
该模块负责通过从操作获取输入并将其传递给用户来生成用户响应。
总结
对话聊天机器人可以使用自然语言工具包构建 – 但随后需要构建更多组件来保存对话上下文和其他内容。 Rasa 通过提供框架使事情变得更加容易,您只需在配置中进行少量更改即可更改内容。甚至像情感分析这样的自定义组件也可以添加为 NLU Pipeline 的一部分。