
手写识别的烦恼
想象一下这个场景:你正在开发一个能识别手写数字的APP,准备让爷爷奶奶也能用手机记账。结果第一版模型训练出来,你兴冲冲地让奶奶写个”8″,模型愣是识别成了”0″。奶奶瞪着眼说:”这比我老花眼还严重!”
你可能会想:”是不是网络不够深?我再加几层!”
等等,兄弟!这就像孩子成绩不好,你就给他报10个补习班一样。问题可能不在于”不够多”,而在于”方法不对”。
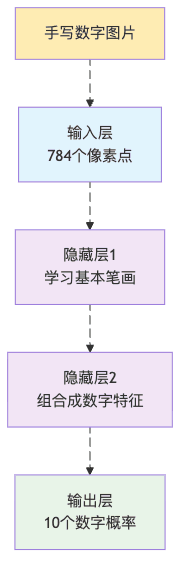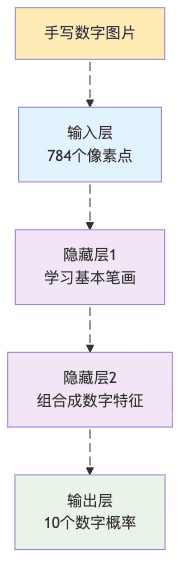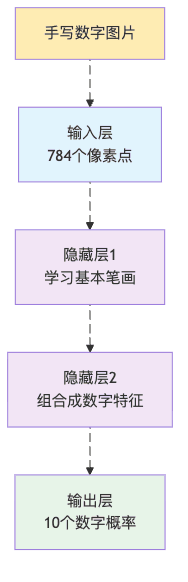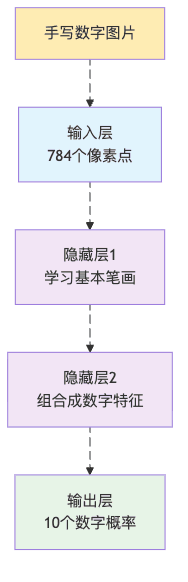
神经网络架构:搭积木也有门道
网络形状 – 你家有几口人?
神经网络的架构就像规划一个家庭:
- 输入层:就像家里的大门,决定能接收多少种信息
- 隐藏层:像是家庭成员,每个人都有不同的技能
- 输出层:就像家长做最终决定
拿手写数字识别来说,网络形状 [784, 128, 64, 10] 意思是:
- 784个输入(28×28像素的图片)
- 第一个隐藏层128个神经元(专门识别线条和弯曲)
- 第二个隐藏层64个神经元(组合成数字特征)
- 输出层10个神经元(对应数字0-9)
你可能会问:”层数越多越聪明吗?”
这就像问”补习班越多成绩越好吗?”答案显然不是。太多层会让网络”消化不良”,就像给小学生教微积分一样。
激活函数:神经元的性格决定一切
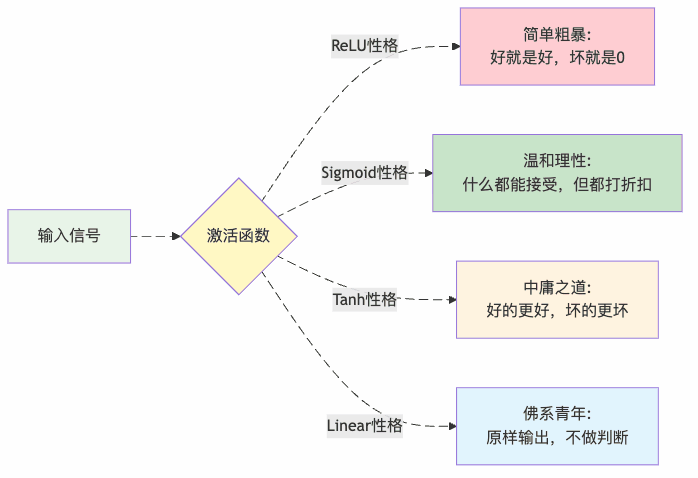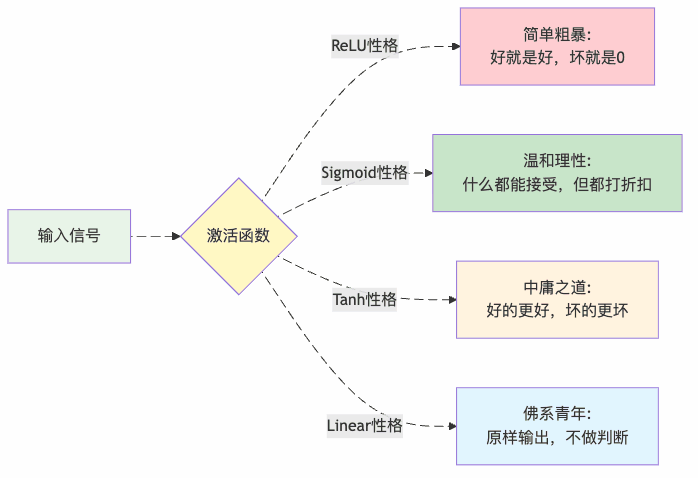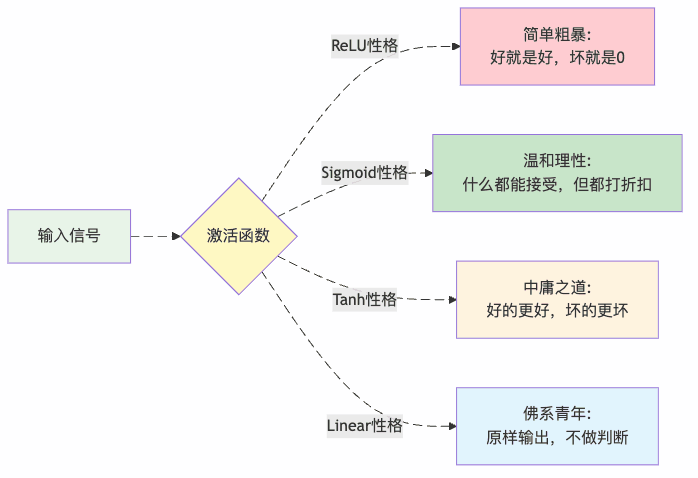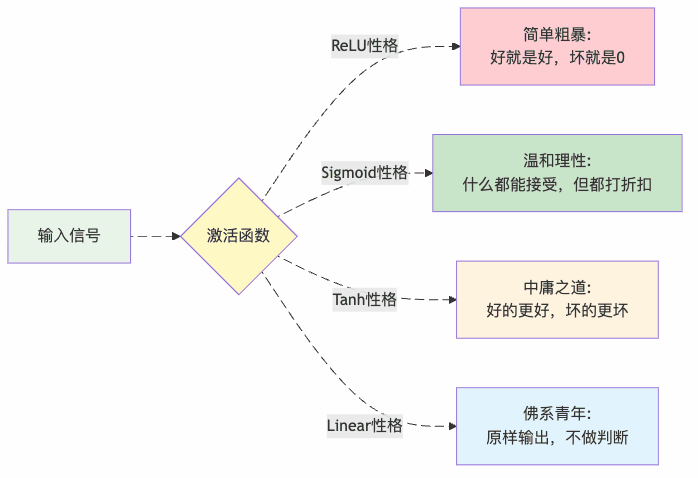
ReLU – 程序员性格
f(x) = max(0, x)ReLU就像典型的程序员:
- 要么全力以赴(x > 0时原样输出)
- 要么摆烂躺平(x ≤ 0时直接输出0)
优点:计算简单,不会”梯度消失”
缺点:有时候太极端,一些神经元可能”英年早逝”
适用场景:大部分隐藏层的首选,就像招聘时更喜欢有执行力的员工
Sigmoid – 和事佬性格
f(x) = 1 / (1 + e^(-x))Sigmoid就像办公室里的和事佬:
- 任何输入都能给你一个0-1之间的”外交辞令”
- 永远不会说”绝对不可能”或”百分百确定”
优点:输出平滑,适合概率解释
缺点:在极端值时”不表态”(梯度接近0)
适用场景:二分类问题的输出层,像是做”是/否”的判断
Tanh – 中庸之道
f(x) = tanh(x)Tanh像是有原则的中庸主义者:
- 输出范围[-1, 1],零中心化
- 比Sigmoid更有态度,但不至于太极端
适用场景:隐藏层的经典选择,平衡性能和稳定性
学习参数:教育孩子的艺术
学习率 – 步子大了容易扯着蛋
想象你在教孩子骑自行车:
- 学习率太大(0.1+):就像你松手后大喊”自己骑!”孩子直接摔个狗吃屎
- 学习率太小(0.001-):你扶得死紧,孩子永远学不会独立骑行
- 学习率合适(0.01-0.1):你逐渐松手,让孩子在摔倒和平衡中找到感觉

批量大小 – 因材施教还是大锅饭?
这就像班主任的选择困难症:
小批量(batch_size = 10):
就像小班教学,每个学生都能得到关注,但老师要频繁调整教学方法,有点累。
大批量(batch_size = 100):
像是大班授课,教学稳定,但可能忽略了个别学生的特殊情况。
实际应用建议:
- 数据量小:用小批量(32-64)
- 数据量大:用中等批量(128-256)
- GPU内存有限:再小一点(16-32)
正则化:防止孩子变成书呆子
L1正则化 – 断舍离大师
L1正则化就像Marie Kondo整理师:
- 看到不重要的权重就说:”这个不spark joy,扔掉!”
- 最终留下的都是精华,模型变得简洁
公式:惩罚项 = λ × Σ|w_i|
适用场景:特征选择,当你有100个特征但只想保留最重要的10个时
L2正则化 – 中庸之道
L2正则化像是温和的家长:
- 不会完全否定任何权重
- 只是温柔地说:”都重要,但都要适度一点”
公式:惩罚项 = λ × Σw_i²
适用场景:防止过拟合的万能选择,大部分情况下的首选
数据处理:巧妇难为无米之炊
训练数据比例 – 练习和考试的平衡
就像学生备考:
- 训练集(70-80%):日常练习题,用来学习知识点
- 测试集(20-30%):模拟考试,检验真实水平
如果把所有题都拿来练习,考试时遇到新题型就懵了(过拟合)。
噪声水平 – 适当的挫折教育
给数据加噪声就像对孩子进行”挫折教育”:
- 让模型在不完美的环境中学习
- 提高对真实世界复杂情况的适应能力
- 防止模型变成温室里的花朵
特征工程:给模型开天眼
原始的x、y坐标就像是素颜照片,而特征工程就像是P图技术:
- x²、y²:突出重点区域
- x×y:发现隐藏关系
- sin(x)、cos(y):捕捉周期性模式
这就像给侦探提供线索:线索越丰富,破案越容易。
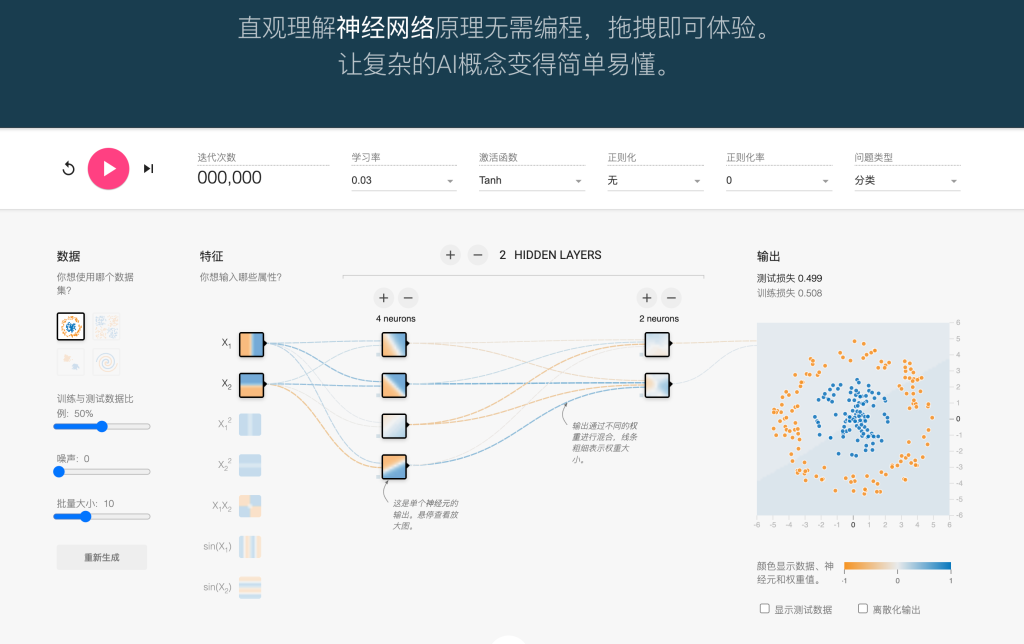
神经网络可视化:让AI不再是黑盒子
说了这么多参数,你可能觉得头大:”这么多参数,我怎么知道调哪个?”
这就是神经网络可视化工具的价值所在!
可视化的好处
- 实时反馈:就像给孩子的作业打分,立刻看到结果
- 参数影响直观:拖动滑块就能看到效果变化
- 学习过程透明:不再是”盲调参数”
- 快速试错:几秒钟就能测试一种配置
推荐工具
文章开头提到的那个手写识别问题?用神经网络可视化工具几分钟就能找到最佳参数配置。
你可以:
- 实时调整学习率,看训练曲线的变化
- 比较不同激活函数的效果
- 观察网络层数对分类边界的影响
- 直观理解过拟合和欠拟合
就像有了GPS导航,再也不会在调参的迷宫里绕圈了。
实战建议:从入门到放弃的避坑指南
新手三板斧
- 先用默认参数跑通流程:就像学车先熟悉油门刹车
- 调学习率看效果:从0.01开始,效果不好就调0.1或0.001
- 加正则化防过拟合:L2正则化率从0.01开始尝试
进阶调优策略
- 网络深度:先浅后深,能解决问题就别加层
- 批量大小:根据GPU内存和数据量平衡
- 特征工程:根据问题特点选择合适的特征组合
常见错误避坑
❌ 误区1:网络越深越好
✅ 正解:够用就好,简单有效胜过复杂难调
❌ 误区2:学习率越大训练越快
✅ 正解:稳定收敛比快速震荡更重要
❌ 误区3:所有层都用同一个激活函数
✅ 正解:隐藏层和输出层要根据任务选择
总结:养孩子和训练神经网络的哲学
训练神经网络真的很像教育孩子:
- 架构设计像是基因遗传,决定了天赋上限
- 参数调节像是后天教育,决定了能发挥多少潜力
- 数据质量像是成长环境,垃圾进垃圾出
- 正则化像是规矩约束,防止走歪路
- 可视化像是成长记录,让进步看得见
记住:好的神经网络不是调出来的,是理解出来的。当你真正理解每个参数的作用时,调参就从玄学变成了科学。
最后,别忘了用可视化工具来辅助学习。毕竟,看得见的进步才是真的进步!
希望这篇文章能让你在神经网络的世界里少走弯路,多一些”原来如此”的顿悟时刻。记住,每个参数背后都有它的道理,理解了原理,调参就不再是玄学!