
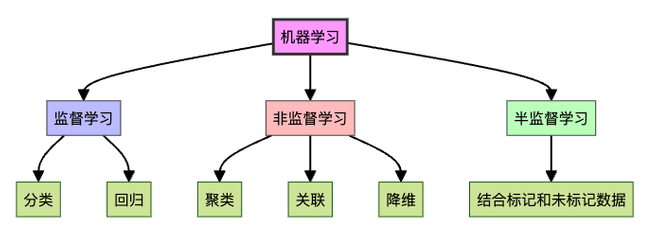
在机器学习的江湖中,监督学习和非监督学习就像是两位武林高手,各有绝技,各领风骚。作为AI世界的入门者,你可能会疑惑:这两种学习方式到底有什么区别?哪一种更适合我的需求?别急,今天我们就来一探究竟!
监督学习:带着”标签”闯江湖
想象一下,监督学习就像是有一位耐心的老师,手把手教你识别事物。在这个过程中,每一个训练样本都贴有正确答案的”标签”。
监督学习的核心就是:算法通过已标记的数据学习,然后尝试预测新数据的标签。就像你小时候学认字一样,爸妈指着”苹果”的图片告诉你这是”苹果”,指着”香蕉”告诉你这是”香蕉”,久而久之,你就能自己认识新的水果了。
监督学习主要分为两大类:
1. 分类问题
在分类问题中,输出是离散的类别标签,比如”垃圾邮件”或”非垃圾邮件”。常见的分类算法包括:
- 线性分类器
- 支持向量机(SVM)
- 决策树
- 随机森林
2. 回归问题
回归问题的输出是连续的值,如房价或概率。常见的回归算法有:
- 线性回归
- 逻辑回归
非监督学习:无师自通的独行侠
而非监督学习则像是一个不需要老师指导的天才,它能够自己发现数据中隐藏的模式和结构,无需人工干预。
非监督学习主要用于三大任务:
1. 聚类
聚类算法将相似的数据样本归为一组。就像是在一个嘈杂的派对上,你能自然地发现”站在一起聊动漫的一群人”、”讨论体育的另一群人”,尽管没人告诉你这些分组。
商家经常用聚类进行客户细分,根据年龄、位置或消费习惯将客户分组,从而制定针对性的营销策略。
2. 关联规则学习
关联规则学习寻找数据变量之间的关系。电商网站最喜欢这一招了:”购买了这个商品的顾客也购买了…”,就是这种算法的杰作。
3. 降维
降维技术减少数据的变量数量,同时尽可能保留信息。这就像是把一篇长文章压缩成几个关键句子,虽然字数少了,但核心意思还在。
这种技术常用于数据预处理阶段,比如自动编码器去除图像噪声以提高图片质量。

两者大PK:谁更胜一筹?
监督学习和非监督学习各有千秋,下面我们通过表格来直观对比两者的优劣势:
| 对比维度 | 监督学习 | 非监督学习 |
|---|---|---|
| 优势 | • 精确度高 • 结果可靠 • 应用广泛 | • 不需要标记数据 • 可以发现隐藏模式 • 实时处理大数据 |
| 劣势 | • 需要大量标记数据 • 标记过程耗时费力 • 可能存在人为偏见 | • 结果不太透明 • 准确度较低 • 应用场景相对有限 |
| 适用场景 | • 已知目标类别 • 需要高精度预测 • 有足够标记数据 | • 探索性数据分析 • 异常检测 • 数据分组与降维 |
半监督学习:鱼和熊掌可以兼得
“等等,我两种方法都想要!”别着急,机器学习界的”折中派”——半监督学习来了。
半监督学习结合了少量标记数据和大量未标记数据,在难以提取特征或数据量巨大时特别有用。
想象一下,在医学影像诊断中,放射科医生可以标记少量CT扫描中的肿瘤或疾病,然后算法就能更准确地预测哪些患者可能需要更多医疗关注,而无需标记整个数据集。这就是半监督学习的魅力所在!
如何选择适合你的学习模型?
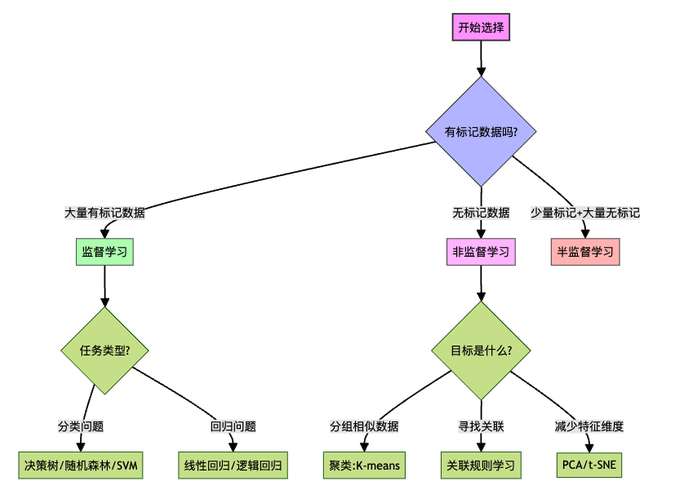
选择机器学习模型时,需要考虑:
- 数据类型:有标签数据?无标签数据?还是混合型?
- 目标任务:预测?分类?还是发现模式?
- 资源限制:有多少时间和人力用于数据标注?
记住,选择监督学习还是非监督学习只是第一步。实际应用中,往往需要多种方法相互配合,才能解决复杂的现实问题。
写在最后
机器学习模型是获取数据洞察的强大工具,选择适合自己数据和目标的模型至关重要。不管是监督学习的精准可靠,还是非监督学习的自主发现,亦或是半监督学习的灵活折中,它们都在不同场景下大放异彩。
所以,监督学习和非监督学习,到底哪个是你的”真命天子”?答案是:取决于你的具体需求和数据特性!在AI的世界里,没有万能钥匙,只有最适合的工具。
你有什么问题或经验想分享吗?欢迎在下方留言讨论!如果喜欢这篇文章,别忘了点赞关注!